Query Plan Architecture: Pattern per i Trigger Apex
Scopri come strutturare trigger complessi in Salesforce con il pattern Query Plan Architecture. Separa la logica in 4 fasi (Collect, Load, Run, Commit) per eliminare SOQL duplicati, rispettare i governor limit e semplificare il testing.
Visualizza il codice sorgente completo su GitHub: salesforce-query-plan-architecture
Cos’è questo pattern?
Query Plan Architecture è un design pattern per strutturare la logica interna di qualsiasi Trigger Handler in Salesforce Apex. Si applica a qualsiasi SObject e qualsiasi evento di trigger (beforeInsert, beforeUpdate, afterInsert, afterUpdate, ecc.).
Il suo obiettivo è risolvere il problema classico dei trigger complessi: molteplici funzionalità che eseguono ciascuna le proprie query SOQL in modo indipendente, generando codice difficile da mantenere, query duplicate e il rischio di superare i governor limit.
Il pattern divide l’esecuzione di ogni “feature” (funzionalità) in 4 fasi chiaramente differenziate, applicando il principio di separazione delle responsabilità:
| Fase | Responsabile | Cosa fa |
|---|---|---|
| 1. COLLECT | TriggerFeature.collect() | Dichiara i dati necessari (senza eseguire query) |
| 2. LOAD | TriggerDataset.load() | Esegue tutte le query SOQL in un singolo passaggio |
| 3. RUN | TriggerFeature.run() | Esegue la logica di business con i dati già caricati |
| 4. COMMIT | fflib_ISObjectUnitOfWork | Persiste tutte le modifiche DML (solo negli eventi AFTER) |
Nota importante su BEFORE vs AFTER:
- Negli eventi BEFORE (
beforeInsert,beforeUpdate): le fasi COLLECT, LOAD e RUN si applicano allo stesso modo. La fase COMMIT non si applica perché i record non hanno ancora un ID e Salesforce gestisce la persistenza alla fine del contesto before.- Negli eventi AFTER (
afterInsert,afterUpdate): tutte le fasi si applicano, incluso COMMIT conuow.commitWork().
Componenti del pattern
Ogni SObject che implementa questo pattern avrà il proprio set di classi con il prefisso dell’oggetto. Gli esempi usano Lead come riferimento, ma il pattern è identico per qualsiasi altro oggetto.
1. [Object]Context
Incapsula i dati del trigger (Trigger.new, Trigger.oldMap, operazione) e fornisce accessor tipizzati e helper di business senza eseguire alcuna query SOQL.
// Esempio generico
public class LeadContext extends BaseTriggerContext {
public LeadContext(List<Lead> newList, Map<Id, Lead> oldMap, TriggerOperation op) {
super(newList, oldMap, op);
}
public List<Lead> getLeads() { return (List<Lead>) this.newList; }
public Lead getOldLead(Id id) { return (Lead) this.oldMap?.get(id); }
// Helper di business specifici dell'oggetto...
public Boolean statusChanged(Lead newLead, Lead oldLead) { ... }
}Responsabilità:
- Fornire accesso tipizzato a
Trigger.neweTrigger.oldMap - Esporre l’operazione del trigger (
BEFORE_INSERT,AFTER_UPDATE, ecc.) - Contenere helper di business riutilizzabili tra le Feature
- Non fare mai SOQL
Nota su
BaseTriggerContext: Estendendo questa classe base, il Context gestisce già internamente il casting diTrigger.neweTrigger.oldMapal tipo corretto. Questo evita che ogni Feature debba fare il proprio casting manuale, riducendo errori e codice ripetitivo. I metodi tipizzati (getLeads(),getOldLead()) sono semplici wrapper su dati già castati nel costruttore.
2. [Object]QueryPlan
Agisce come un oggetto di configurazione accumulatore (“lista della spesa”). Le Feature lo popolano durante la fase COLLECT per dichiarare quali dati avranno bisogno nella fase RUN. Non esegue alcuna query.
// Esempio generico
public class LeadQueryPlan {
public Boolean needDelegadoComercialUsers { get; set; }
public Set<Id> delegationIdsForDelegadoComercial { get; private set; }
public LeadQueryPlan() {
this.needDelegadoComercialUsers = false;
this.delegationIdsForDelegadoComercial = new Set<Id>();
}
// Metodo fluent: consente il concatenamento e accumula gli ID da più feature
public LeadQueryPlan requireDelegadoComercialUsers(Set<Id> ids) {
this.needDelegadoComercialUsers = true;
if (ids != null) { this.delegationIdsForDelegadoComercial.addAll(ids); }
return this;
}
// Utilità di debug
public String getSummary() { ... }
}Responsabilità:
- Accumulare gli ID e i flag di tutte le Feature in un singolo passaggio
- Evitare query duplicate (se 5 Feature hanno bisogno degli stessi dati, il piano li carica solo una volta)
- Non fare mai SOQL
3. [Object]Dataset
Questa è l’UNICA classe che esegue query SOQL nel contesto del trigger. Riceve il QueryPlan già popolato, esegue le query minime necessarie e mette in cache i risultati per il resto della transazione.
// Esempio generico
public inherited sharing class LeadDataset {
public Map<Id, Set<Id>> delegadoComercialUsersByDelegationId { get; private set; }
public LeadDataset() {
this.delegadoComercialUsersByDelegationId = new Map<Id, Set<Id>>();
}
// Unico punto di ingresso per il caricamento dei dati
public void load(LeadQueryPlan plan) {
if (plan == null) { return; }
loadDelegadoComercialUsers(plan);
}
private void loadDelegadoComercialUsers(LeadQueryPlan plan) {
if (!plan.needDelegadoComercialUsers || plan.delegationIdsForDelegadoComercial.isEmpty()) {
return;
}
IDelegationUsersSelector selector =
(IDelegationUsersSelector) Application.Selector.newInstance(DelegationUser__c.SObjectType);
this.delegadoComercialUsersByDelegationId.putAll(
selector.selectDelegadoComercialUserIdsByDelegationIds(plan.delegationIdsForDelegadoComercial)
);
}
public Set<Id> getDelegadoComercialUsers(Id delegationId) {
return this.delegadoComercialUsersByDelegationId.containsKey(delegationId)
? this.delegadoComercialUsersByDelegationId.get(delegationId)
: new Set<Id>();
}
}Responsabilità:
- Essere il solo esecutore di SOQL nel contesto del trigger
- Caricare i dati solo se una Feature ne ha avuto bisogno (valutando i flag del QueryPlan)
- Consolidare gli ID di più feature in una singola query
4. [Object]Feature (classe base astratta)
Classe base di tutte le funzionalità del trigger. Definisce il contratto che devono rispettare:
public abstract class LeadFeature {
// Opzionale: Dichiara i dati necessari. Non fare SOQL qui.
public virtual void collect(LeadQueryPlan plan, LeadContext ctx) { }
// Obbligatorio: Esegue la logica di business
public abstract void run(LeadContext ctx, LeadDataset dataset, fflib_ISObjectUnitOfWork uow);
public String getName() {
return String.valueOf(this).split(':')[0];
}
}collect()è opzionale (virtual vuoto). Da sovrascrivere solo se la Feature ha bisogno di caricare dati dall’esterno.run()è obbligatorio (abstract). Tutta la logica di business va qui.- Negli eventi BEFORE, il parametro
uowarriverà comenull.
Flusso di esecuzione completo
Diagramma visuale del flusso dei dati
Il seguente diagramma mostra come i dati fluiscono orizzontalmente attraverso tutte le feature durante COLLECT, si consolidano in un singolo passaggio verticale verso il database durante LOAD, e poi si ridistribuiscono in memoria durante RUN:
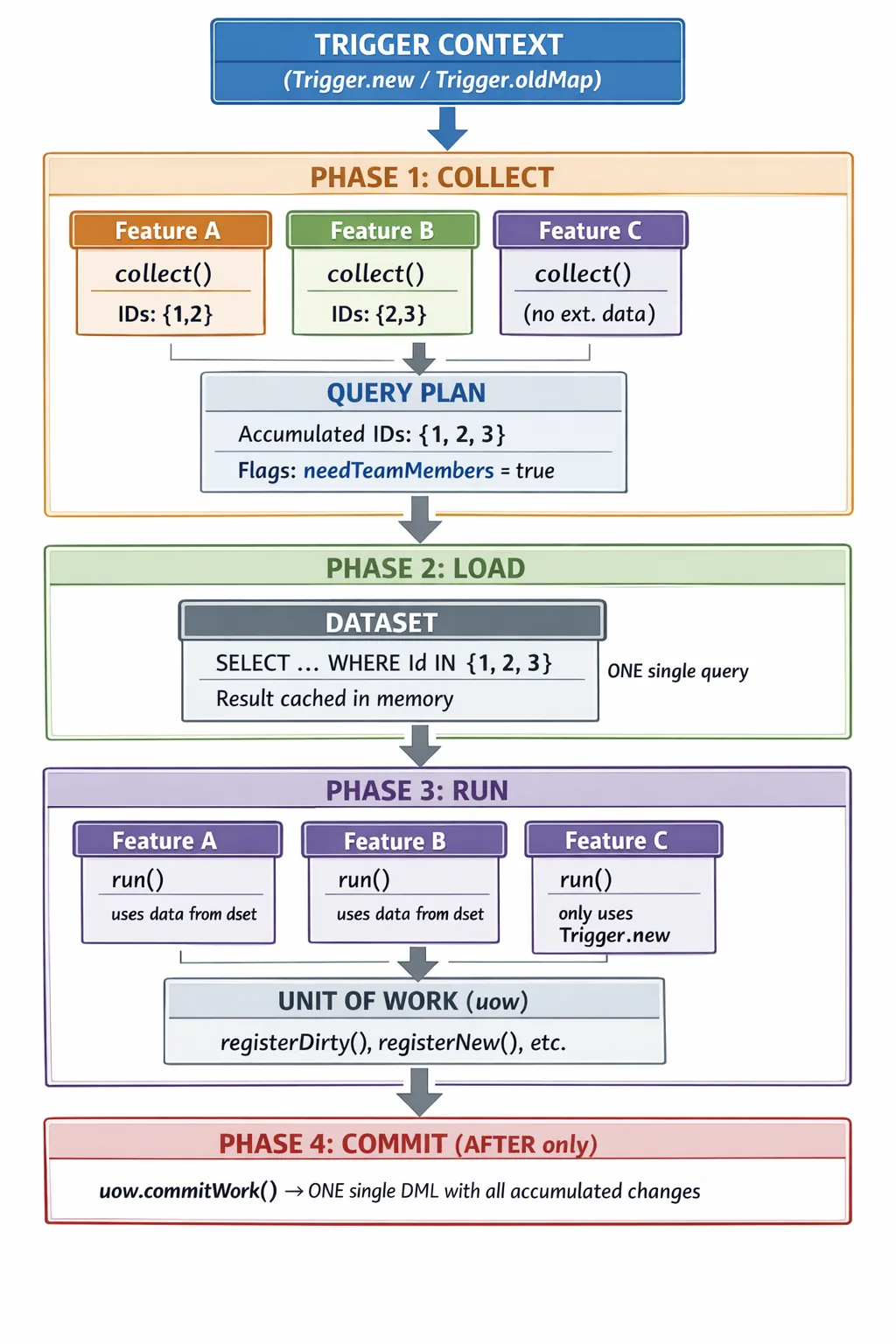
Punti chiave del diagramma:
- Le feature dichiarano i dati necessari in parallelo durante COLLECT, senza eseguire query.
- Il QueryPlan deduplica gli ID automaticamente (2 + 3 = 3).
- Il Dataset esegue una sola query al database con tutti gli ID consolidati.
- Durante RUN, tutte le feature accedono agli stessi dati in memoria (nessuna query aggiuntiva).
- La Feature C non necessita di dati esterni — non partecipa al COLLECT, ma sì al RUN.
Evento AFTER (con COMMIT)
TriggerHandler.afterUpdate() / afterInsert()
└── executeFeatures(ctx, features)
├── [COLLECT] feature1.collect(plan, ctx) ← senza SOQL
├── [COLLECT] feature2.collect(plan, ctx) ← senza SOQL
├── [LOAD] dataset.load(plan) ← UN SOLO passaggio SOQL
├── [RUN] feature1.run(ctx, dataset, uow) ← dati già in memoria
├── [RUN] feature2.run(ctx, dataset, uow) ← dati già in memoria
└── [COMMIT] uow.commitWork() ← DML transazionaleEvento BEFORE (senza COMMIT)
TriggerHandler.beforeInsert() / beforeUpdate()
└── executeFeatures(ctx, features)
├── [COLLECT] feature1.collect(plan, ctx) ← senza SOQL
├── [COLLECT] feature2.collect(plan, ctx) ← senza SOQL
├── [LOAD] dataset.load(plan) ← query SOQL
├── [RUN] feature1.run(ctx, dataset, null) ← uow = null
└── [RUN] feature2.run(ctx, dataset, null) ← modificare i record direttamenteAttenzione con
beforeInsert: In questo evento, i record diTrigger.newnon hanno ID (Idènull). Se la tua feature tenta di accumulare gli ID dei record in ingresso nel QueryPlan (ad esempio,plan.requireRelatedData(newRecord.Id)), questi sarannonulle la query non restituirà risultati. NelbeforeInsert, il QueryPlan deve accumulare solo gli ID di campi relazionali che hanno già un valore (comeAccountId,OwnerId, o campi lookup pre-popolati). Questo è un errore classico che uno sviluppatore junior commetterà usando il framework.
Implementazione dell’orchestratore nel TriggerHandler
public class LeadTriggerHandler extends TriggerHandler {
public override void afterUpdate() {
executeFeatures(
new LeadContext((List<Lead>) Trigger.new, (Map<Id, Lead>) Trigger.oldMap, TriggerOperation.AFTER_UPDATE),
getAfterUpdateFeatures()
);
}
public override void beforeInsert() {
executeFeatures(
new LeadContext((List<Lead>) Trigger.new, null, TriggerOperation.BEFORE_INSERT),
getBeforeInsertFeatures()
);
}
private List<LeadFeature> getAfterUpdateFeatures() {
return new List<LeadFeature>{ new PromoNameNotificationFeature() };
}
private List<LeadFeature> getBeforeInsertFeatures() {
return new List<LeadFeature>{ };
}
private void executeFeatures(LeadContext ctx, List<LeadFeature> features) {
LeadQueryPlan plan = new LeadQueryPlan();
LeadDataset dataset = new LeadDataset();
for (LeadFeature feature : features) { feature.collect(plan, ctx); }
dataset.load(plan);
Boolean isAfterEvent = ctx.operationType == TriggerOperation.AFTER_UPDATE
|| ctx.operationType == TriggerOperation.AFTER_INSERT
|| ctx.operationType == TriggerOperation.AFTER_DELETE;
fflib_ISObjectUnitOfWork uow = isAfterEvent ? Application.UnitOfWork.newInstance() : null;
for (LeadFeature feature : features) {
try {
feature.run(ctx, dataset, uow);
} catch (Exception e) {
Logger.error(new LogMessage('Error in feature {0}: {1}', feature.getName(), e.getMessage()))
.setExceptionDetails(e).addTags(LOGGER_TAGS);
}
}
if (uow != null) {
try { uow.commitWork(); }
catch (Exception ex) { Logger.error('Error in commitWork').setExceptionDetails(ex).addTags(LOGGER_TAGS); }
}
}
}Esempio pratico: ClosedWonFollowUpFeature
Questo esempio usa Opportunity per mostrare che il pattern è valido per qualsiasi SObject. La feature crea un Task di follow-up per ogni membro del team dell’account (AccountTeamMember) quando un’opportunità passa allo stadio “Closed Won”.
Questo caso d’uso illustra chiaramente il valore del QueryPlan: se 50 opportunità di 5 account diversi vengono aggiornate nello stesso trigger, il pattern garantisce che venga eseguita una sola query per caricare tutti gli AccountTeamMember, invece di fino a 50 query individuali.
Impatto reale sui Governor Limits
Scenario: 200 Opportunity aggiornate a “Closed Won”, appartenenti a 15 Account diversi. Due feature devono interrogare
AccountTeamMember.
| Metrica | Senza Query Plan | Con Query Plan | Differenza |
|---|---|---|---|
| Query SOQL eseguite | 400 (200 × 2 feature) | 1 | -99,75% |
| Record interrogati | Duplicati in ogni feature | Un solo caricamento condiviso | Nessun duplicato |
| Supera il limite di 100 SOQL? | Sì — System.LimitException | No — usa 1 su 100 | Transazione sicura |
| Operazioni DML | Sparse in ogni feature | 1 (uow.commitWork()) | Atomico e consolidato |
Risultato: da 400 query che rompono la transazione a 1 sola query che consuma l’1% del governor limit. Questo è il valore principale del pattern — e scala linearmente: più feature che condividono dati = maggiore risparmio.
Classe completa
public class ClosedWonFollowUpFeature extends OpportunityFeature {
// Stato interno tra collect() e run()
private List<Opportunity> closedOpportunities = new List<Opportunity>();
// FASE COLLECT: identifica quali opportunità si sono appena chiuse
// e dichiara quali AccountId il Dataset dovrà caricare
public override void collect(OpportunityQueryPlan plan, OpportunityContext ctx) {
for (Opportunity newOpp : ctx.getOpportunities()) {
Opportunity oldOpp = ctx.getOldOpportunity(newOpp.Id);
if (justClosedWon(newOpp, oldOpp)) {
closedOpportunities.add(newOpp);
plan.requireAccountTeamMembers(newOpp.AccountId);
}
}
}
// FASE RUN: usa i dati già caricati in memoria per creare i task
public override void run(OpportunityContext ctx, OpportunityDataset dataset, fflib_ISObjectUnitOfWork uow) {
for (Opportunity opp : closedOpportunities) {
List<AccountTeamMember> teamMembers = dataset.getAccountTeamMembers(opp.AccountId);
for (AccountTeamMember member : teamMembers) {
uow.registerNew(new Task(
Subject = 'Follow-up post-chiusura: ' + opp.Name,
OwnerId = member.UserId,
WhatId = opp.Id,
ActivityDate = Date.today().addDays(7),
Priority = 'Normal',
Status = 'Not Started'
));
}
}
}
private Boolean justClosedWon(Opportunity newOpp, Opportunity oldOpp) {
return newOpp.StageName == 'Closed Won'
&& (oldOpp == null || oldOpp.StageName != 'Closed Won');
}
}OpportunityQueryPlan e OpportunityDataset dell’esempio
Per comprendere la “magia” completa, ecco le classi che supportano questo esempio:
// OpportunityQueryPlan: accumula le necessità di TUTTE le feature
public class OpportunityQueryPlan {
public Boolean needAccountTeamMembers { get; set; }
public Set<Id> accountIdsForTeamMembers { get; private set; }
public OpportunityQueryPlan() {
this.needAccountTeamMembers = false;
this.accountIdsForTeamMembers = new Set<Id>();
}
// Se 3 feature diverse chiamano questo metodo con ID diversi,
// TUTTI vengono accumulati in un singolo Set → una sola query
public OpportunityQueryPlan requireAccountTeamMembers(Id accountId) {
this.needAccountTeamMembers = true;
if (accountId != null) { this.accountIdsForTeamMembers.add(accountId); }
return this;
}
}// OpportunityDataset: esegue UNA SOLA query con TUTTI gli ID accumulati
public inherited sharing class OpportunityDataset {
private Map<Id, List<AccountTeamMember>> teamMembersByAccountId;
public OpportunityDataset() {
this.teamMembersByAccountId = new Map<Id, List<AccountTeamMember>>();
}
public void load(OpportunityQueryPlan plan) {
if (plan == null) { return; }
loadAccountTeamMembers(plan);
}
private void loadAccountTeamMembers(OpportunityQueryPlan plan) {
if (!plan.needAccountTeamMembers || plan.accountIdsForTeamMembers.isEmpty()) {
return;
}
// UNA SOLA QUERY per tutti gli AccountId di tutte le feature
for (AccountTeamMember atm : [
SELECT Id, UserId, AccountId, TeamMemberRole
FROM AccountTeamMember
WHERE AccountId IN :plan.accountIdsForTeamMembers
]) {
if (!this.teamMembersByAccountId.containsKey(atm.AccountId)) {
this.teamMembersByAccountId.put(atm.AccountId, new List<AccountTeamMember>());
}
this.teamMembersByAccountId.get(atm.AccountId).add(atm);
}
}
public List<AccountTeamMember> getAccountTeamMembers(Id accountId) {
return this.teamMembersByAccountId.containsKey(accountId)
? this.teamMembersByAccountId.get(accountId)
: new List<AccountTeamMember>();
}
}Perché questo esempio illustra bene il pattern?
- COLLECT non fa SOQL: esamina solo i record del trigger e accumula gli
AccountIdnel piano. - LOAD consolida le query: se 50 opportunità appartengono a 5 account, il
DatasetesegueSELECT ... WHERE AccountId IN (5 IDs)una sola volta. - RUN lavora in memoria: usa
dataset.getAccountTeamMembers(id)senza toccare il database. - COMMIT è transazionale: tutti i
Taskvengono inseriti insieme in un singolo DML alla fine.
Come aggiungere una nuova Feature
Non è troppo boilerplate? Dipende dal tipo di feature. Se la tua nuova feature non ha bisogno di dati esterni (opera solo su
Trigger.new), non tocchi né QueryPlan né Dataset — crei semplicemente la classe Feature e la registri nel Handler (passi 1 e 2). Il passo 3 si applica solo quando devi caricare dati aggiuntivi. Sì, ci sono più classi rispetto a un handler monolitico. Ma ogni classe ha una singola responsabilità, è testabile in isolamento, e un nuovo sviluppatore può capire cosa fa una Feature leggendo solo la sua classe, senza navigare 500 righe di un Handler gigantesco.
Passo 1: Creare la classe
public class MiaNuovaFeature extends LeadFeature {
public override void collect(LeadQueryPlan plan, LeadContext ctx) {
Set<Id> ids = new Set<Id>();
for (Lead lead : ctx.getLeads()) {
if (miaCondizione(lead, ctx.getOldLead(lead.Id))) { ids.add(lead.AssignedDelegation__c); }
}
if (!ids.isEmpty()) { plan.requireDelegadoComercialUsers(ids); }
}
public override void run(LeadContext ctx, LeadDataset dataset, fflib_ISObjectUnitOfWork uow) {
for (Lead lead : ctx.getLeads()) {
// Se AFTER: uow.registerDirty(...)
// Se BEFORE: lead.MioCampo__c = valore;
}
}
}Passo 2: Registrare nel TriggerHandler
private List<LeadFeature> getAfterUpdateFeatures() {
return new List<LeadFeature>{
new PromoNameNotificationFeature(),
new MiaNuovaFeature() // Aggiungere qui
};
}Passo 3: Estendere QueryPlan e Dataset (se hai bisogno di nuovi dati)
Nel [Object]QueryPlan:
public Boolean needMieiDati { get; set; }
public Set<Id> idsPerMieiDati { get; private set; }
public LeadQueryPlan requireMieiDati(Set<Id> ids) {
this.needMieiDati = true;
if (ids != null) { this.idsPerMieiDati.addAll(ids); }
return this;
}Nel [Object]Dataset:
private void loadMieiDati(LeadQueryPlan plan) {
if (!plan.needMieiDati || plan.idsPerMieiDati.isEmpty()) { return; }
IMioOggettoSelector selector = (IMioOggettoSelector) Application.Selector.newInstance(MioOggetto__c.SObjectType);
for (MioOggetto__c obj : selector.selectByIds(plan.idsPerMieiDati)) {
this.mieiDati.put(obj.Id, obj);
}
}Benefici del pattern
| Problema precedente | Soluzione con Query Plan |
|---|---|
| Ogni feature faceva il proprio SOQL | Un unico punto di caricamento (Dataset) |
| SOQL duplicati tra feature | Accumulo di ID → una sola query |
| Logica mescolata con le query | Separazione chiara per fasi |
| Difficile da testare in isolamento | Ogni Feature testabile con mock di Context e Dataset |
| DML disperso in tutto il trigger | Un solo uow.commitWork() alla fine |
| Trigger monolitico difficile da estendere | Aggiungere Feature = creare una classe, senza toccare il codice esistente |
Considerazioni sulla scalabilità
E se ho 50 feature su un singolo oggetto?
Se un SObject come Account ha 50 processi di business distinti, il QueryPlan potrebbe crescere fino a decine di flag e metodi require. Questo è un segnale che l’oggetto ha troppa responsabilità accumulata. Prima di preoccuparti della dimensione del QueryPlan, valuta:
- Tutte le feature appartengono al trigger? Spesso, la logica che si trova in un trigger dovrebbe essere un Platform Event, un Flow o un Queueable. Migra ciò che non è critico fuori dal contesto sincrono.
- Raggruppa per dominio funzionale: Se il QueryPlan cresce troppo, puoi raggruppare i dati correlati usando inner class o composizione:
plan.billing().requireInvoices(ids),plan.team().requireMembers(ids). Ogni gruppo incapsula il proprio set di flag. - Nella pratica, la maggior parte degli SObject ha tra 5 e 15 feature per evento di trigger. Il QueryPlan rimane leggibile e gestibile a quella scala.
Consumo di Heap Size
Il Dataset mantiene una sola copia dei dati in memoria, condivisa tra tutte le Feature. Questo è più efficiente dell’approccio senza pattern dove ogni feature memorizza la propria copia del risultato.
Tuttavia, tieni presenti questi limiti per le transazioni massive (200 record):
- Heap Size: 6 MB in contesto sincrono, 12 MB in asincrono.
- Mitigazioni: limita i campi nel SELECT del Selector (solo quelli necessari), usa query con LIMIT se il caso d’uso lo permette, e nei casi estremi considera
Database.executeBatchper l’elaborazione a blocchi. - Regola generale: il caso peggiore di heap con questo pattern è uguale o inferiore a quello senza pattern, perché il consolidamento delle query elimina i dati duplicati in memoria.
Query Plan vs fflib Selector Layer
Se usi già fflib, probabilmente ti chiedi: “Il Selector Layer non risolve già questo?” La risposta è che Query Plan non sostituisce i Selectors — li orchestra.
| Aspetto | fflib Selector Layer | Query Plan Architecture |
|---|---|---|
| Chi decide cosa caricare | Ogni consumatore chiama il Selector quando vuole | Le Feature dichiarano le necessità; il Dataset carica tutto insieme |
| Momento della query | Disperso (ogni Service o Domain chiama per conto suo) | Consolidato (una sola fase LOAD prima di eseguire la logica) |
| Deduplicazione degli ID | Non automatica (se 3 servizi richiedono gli stessi ID, sono 3 query) | Automatica (il QueryPlan accumula ID unici in un Set) |
| Scope | Generico per tutta l’applicazione | Specifico per il contesto del Trigger |
| Chi esegue la query | Il Selector direttamente | Il Dataset chiama il Selector internamente |
Il punto chiave: i Selectors fflib ti dicono COME fare la query (quali campi, quali filtri, quale ordine). Il QueryPlan ti dice QUANDO e CON QUALI dati farla, consolidando più consumatori in una singola esecuzione. Infatti, se guardi il codice del Dataset, vedrai che internamente usa i Selectors fflib:
// Il Dataset USA il Selector fflib — non lo sostituisce
IDelegationUsersSelector selector =
(IDelegationUsersSelector) Application.Selector.newInstance(DelegationUser__c.SObjectType);Struttura dei file
force-app/main/default/classes/[Object]/
├── Context/
│ ├── [Object]Context.cls
│ └── [Object]ContextTest.cls
├── QueryPlan/
│ ├── [Object]QueryPlan.cls
│ └── [Object]QueryPlanTest.cls
├── Dataset/
│ └── [Object]Dataset.cls
├── Feature/
│ ├── [Object]Feature.cls
│ ├── MiaFeature1.cls
│ └── MiaFeature1Test.cls
└── TriggerHandler/
└── [Object]TriggerHandler.clsRegole del pattern (obbligatorie)
- SOQL solo nel
[Object]Dataset— Nessuna Feature, Context o TriggerHandler può fare query dirette. - DML solo tramite UnitOfWork — Negli eventi AFTER, registrare in
uow. Mai DML diretto nelle Feature. collect()è in sola lettura — Dichiara solo le necessità al piano, non modifica record e non fa SOQL.- Stato interno della Feature — Se una Feature conserva uno stato tra
collect()erun(), deve essere un campo di istanza privato. - Non usare
Trigger.newdirettamente nelle Feature — Usare semprectx.getLeads()o l’equivalente tipizzato. - Una Feature = una responsabilità — Se una Feature deve fare più di una cosa, dividerla in due.
- Negli eventi BEFORE,
uowè null — Verificare seuow != nullprima di usarlo, o modificare i record direttamente nel contesto.
Fondamenti teorici dell’architettura
Questa architettura non emerge dal nulla. È una composizione deliberata di quattro pattern ben consolidati, ognuno dei quali risolve una dimensione diversa del problema.
1. Template Method — Lo scheletro del ciclo di vita
Fonte: Design Patterns: Elements of Reusable Object-Oriented Software — Gang of Four (1994).
Scopo originale: Definire lo scheletro di un algoritmo in una classe astratta, delegando i passaggi concreti alle sottoclassi, senza permettere loro di alterare la struttura generale dell’algoritmo.
Come si applica qui:
La classe astratta [Object]Feature definisce il ciclo di vita obbligatorio di qualsiasi funzionalità del trigger: prima collect(), poi run(). Questo ordine è controllato dall’orchestratore (executeFeatures), non da ogni Feature. Le sottoclassi concrete implementano solo i passi specifici, senza poter saltare o riordinare le fasi.
[Object]Feature (astratta)
├── collect() → hook opzionale (virtual vuoto per default)
└── run() → hook obbligatorio (abstract, senza implementazione)
PromoNameNotificationFeature (concreta)
├── collect() → dichiara quali delegazioni necessita
└── run() → invia notifiche usando dati pre-caricatiSenza questo pattern, ogni sviluppatore potrebbe inventare la propria convenzione per strutturare una feature, rompendo la coerenza del framework.
2. Strategy — L’intercambiabilità delle Feature
Fonte: Design Patterns: Elements of Reusable Object-Oriented Software — Gang of Four (1994).
Scopo originale: Definire una famiglia di algoritmi, incapsulare ognuno in una classe separata e renderli intercambiabili senza modificare il codice client che li utilizza.
Come si applica qui:
Il TriggerHandler non contiene logica di business rigida. Invece, delega a una lista di Feature selezionabili per evento. Ogni evento ha la propria lista di “strategie” attive (getAfterUpdateFeatures(), getBeforeInsertFeatures(), ecc.).
// Il TriggerHandler itera solo sull'interfaccia comune
for (LeadFeature feature : features) {
feature.collect(plan, ctx); // non sa cosa fa ogni feature concreta
}Questo consente di aggiungere, rimuovere o sostituire una Feature senza toccare nulla nell’orchestratore. L’estensibilità è il suo principale contributo: nuova funzionalità = nuova classe, senza modificare il codice esistente (principio Open/Closed).
3. DataLoader — L’efficienza del QueryPlan
Fonte: Facebook Engineering, 2010. Pubblicato come libreria open source nel 2015.
Scopo originale: Risolvere il problema N+1 delle query nelle applicazioni con più consumatori di dati indipendenti. Invece che ogni consumatore faccia la propria query, DataLoader accumula tutte le chiavi richieste in un singolo “tick” e le risolve in un’unica chiamata al backend (batching).
Il problema N+1 che risolve:
// SENZA DataLoader: N consumatori = N query
feature1 → SELECT ... WHERE DelegationId__c = 'a'
feature2 → SELECT ... WHERE DelegationId__c = 'b'
feature3 → SELECT ... WHERE DelegationId__c = 'a' ← duplicata!
// CON DataLoader (QueryPlan): N consumatori = 1 query
collect() → piano accumula {'a', 'b'} dalle 3 feature
load() → SELECT ... WHERE DelegationId__c IN ('a', 'b')Mappato al framework:
| DataLoader (JavaScript) | Query Plan Architecture (Apex) |
|---|---|
dataloader.load(key) | plan.requireXYZ(ids) in collect() |
| Accumulo nell’event loop | Accumulo nella fase COLLECT |
batchLoadFn(keys[]) | dataset.load(plan) |
dataloader.get(key) | dataset.getXYZ(id) in run() |
| Cache per richiesta | Dataset in memoria per transazione |
Questo è il pattern più critico dell’architettura. È la ragione d’esistere del QueryPlan e del Dataset: separare il momento in cui il bisogno viene dichiarato dal momento in cui viene risolto, consentendo la consolidazione automatica tra tutte le Feature.
4. Unit of Work — Il consolidamento del DML
Fonte: Patterns of Enterprise Application Architecture — Martin Fowler, 2002. Implementazione Salesforce: fflib-apex-common (Apex Enterprise Patterns).
Scopo originale: Mantenere un registro di tutti gli oggetti influenzati da una transazione di business e coordinare la scrittura delle modifiche alla fine, invece di eseguire operazioni di database sparse durante la transazione.
Come si applica qui:
Durante la fase RUN, nessuna Feature esegue DML direttamente. Invece, registra le operazioni nel UnitOfWork:
// La Feature registra, non esegue
uow.registerDirty(lead); // UPDATE in attesa
uow.registerNew(event); // INSERT in attesa
uow.registerPublishAfterSuccessTransaction(platformEvent); // PUBLISH in attesa
// Solo alla fine di executeFeatures, tutto viene materializzato:
uow.commitWork(); // UN solo DML con tutte le modifiche accumulateQuesto garantisce che l’intera transazione sia atomica: o tutto viene persistito correttamente o nulla viene persistito. Minimizza inoltre il numero di operazioni DML consumate dai governor limit di Salesforce.
Unit of Work complementa il pattern DataLoader: DataLoader consolida le letture (SOQL), Unit of Work consolida le scritture (DML). Insieme, garantiscono il minimo consumo possibile di governor limit durante tutta l’esecuzione.
Mappa di corrispondenza: pattern ↔ componente
| Pattern | Componente nel framework | Cosa risolve |
|---|---|---|
| Template Method | [Object]Feature (astratta) | Ciclo di vita uniforme per tutte le Feature |
| Strategy | Liste get[Evento]Features() | Estensibilità senza modificare l’orchestratore |
| DataLoader | [Object]QueryPlan + [Object]Dataset | Consolidamento SOQL tra più Feature |
| Unit of Work | fflib_ISObjectUnitOfWork in executeFeatures | Consolidamento DML in una singola transazione |
Articoli Correlati
 Salesforce
Salesforce Bulk DML Service Pattern: Operazioni DML Parziali in Salesforce
Documentazione tecnica completa del framework Bulk DML Service Pattern per Salesforce. Impara a realizzare operazioni DML resilienti con successo parziale usando un API familiare in stile Unit of Work.
 Salesforce
Salesforce Architettura Salesforce con FFLib: Pattern Enterprise
Guida completa all'implementazione dei pattern architetturali enterprise in Salesforce usando FFLib. Include Domain Layer, Selector Layer, Service Layer e Unit of Work.
 Salesforce In evidenza
Salesforce In evidenza CI/CD per Salesforce: Automazione dei Deploy
Implementazione completa di pipeline CI/CD per Salesforce usando GitHub Actions, SFDX CLI e Scratch Orgs. Include best practice e troubleshooting.