Query Plan Architecture: Patrón para Triggers Apex
Descubre cómo estructurar triggers complejos en Salesforce con el patrón Query Plan Architecture. Separa la lógica en 4 fases (Collect, Load, Run, Commit) para eliminar SOQL duplicados, respetar governor limits y facilitar el testing.
Ver el código fuente completo en GitHub: salesforce-query-plan-architecture
¿Qué es este patrón?
El Query Plan Architecture es un patrón de diseño para estructurar la lógica interna de cualquier Trigger Handler en Salesforce Apex. Se aplica a cualquier SObject y cualquier evento de trigger (beforeInsert, beforeUpdate, afterInsert, afterUpdate, etc.).
Su objetivo es resolver el problema clásico de los triggers complejos: múltiples funcionalidades que cada una hace sus propias queries SOQL de forma independiente, generando código difícil de mantener, queries duplicadas y riesgo de superar governor limits.
El patrón divide la ejecución de cada “feature” (funcionalidad) en 4 fases bien diferenciadas, aplicando el principio de separación de responsabilidades:
| Fase | Responsable | ¿Qué hace? |
|---|---|---|
| 1. COLLECT | TriggerFeature.collect() | Declara qué datos necesita (sin hacer queries) |
| 2. LOAD | TriggerDataset.load() | Ejecuta todas las queries SOQL de una sola vez |
| 3. RUN | TriggerFeature.run() | Ejecuta la lógica de negocio usando datos ya cargados |
| 4. COMMIT | fflib_ISObjectUnitOfWork | Persiste todos los cambios DML (solo en eventos AFTER) |
Componentes del patrón
Cada SObject que implemente este patrón tendrá su propio conjunto de clases con el prefijo del objeto. En los ejemplos se usa Lead como referencia, pero el patrón es idéntico para cualquier otro objeto.
1. [Object]Context
Encapsula los datos del trigger (Trigger.new, Trigger.oldMap, operación) y proporciona accessors tipados y helpers de negocio sin ejecutar ninguna query SOQL.
// Ejemplo genérico
public class LeadContext extends BaseTriggerContext {
public LeadContext(List<Lead> newList, Map<Id, Lead> oldMap, TriggerOperation op) {
super(newList, oldMap, op);
}
public List<Lead> getLeads() { return (List<Lead>) this.newList; }
public Lead getOldLead(Id id) { return (Lead) this.oldMap?.get(id); }
// Helpers de negocio específicos del objeto...
public Boolean statusChanged(Lead newLead, Lead oldLead) { ... }
}Responsabilidades:
- Proveer acceso tipado a
Trigger.newyTrigger.oldMap - Exponer la operación del trigger (
BEFORE_INSERT,AFTER_UPDATE, etc.) - Contener helpers de negocio reutilizables entre Features
- Nunca hacer SOQL
Nota sobre
BaseTriggerContext: Al extender esta clase base, el Context ya gestiona internamente el casting deTrigger.newyTrigger.oldMapal tipo correcto. Esto evita que cada Feature tenga que hacer su propio casting manual, reduciendo errores y código repetitivo. Los métodos tipados (getLeads(),getOldLead()) son simples wrappers sobre datos ya casteados en el constructor.
2. [Object]QueryPlan
Actúa como un objeto de configuración acumulador (“lista de la compra”). Las Features lo populan durante la fase COLLECT para declarar qué datos necesitarán en la fase RUN. No ejecuta ninguna query.
// Ejemplo genérico
public class LeadQueryPlan {
public Boolean needDelegadoComercialUsers { get; set; }
public Set<Id> delegationIdsForDelegadoComercial { get; private set; }
public LeadQueryPlan() {
this.needDelegadoComercialUsers = false;
this.delegationIdsForDelegadoComercial = new Set<Id>();
}
// Método fluent: permite encadenar y acumula IDs de múltiples features
public LeadQueryPlan requireDelegadoComercialUsers(Set<Id> ids) {
this.needDelegadoComercialUsers = true;
if (ids != null) { this.delegationIdsForDelegadoComercial.addAll(ids); }
return this;
}
// Utilidad de debug
public String getSummary() { ... }
}Responsabilidades:
- Acumular IDs y flags de todas las Features en una sola pasada
- Evitar queries duplicadas (si 5 Features necesitan el mismo dato, el plan solo lo carga una vez)
- Nunca hacer SOQL
3. [Object]Dataset
Esta es la ÚNICA clase que ejecuta SOQL queries dentro del contexto del trigger. Recibe el QueryPlan ya populado, ejecuta las queries mínimas y necesarias, y cachea los resultados para el resto de la transacción.
// Ejemplo genérico
public inherited sharing class LeadDataset {
public Map<Id, Set<Id>> delegadoComercialUsersByDelegationId { get; private set; }
public LeadDataset() {
this.delegadoComercialUsersByDelegationId = new Map<Id, Set<Id>>();
}
// Único punto de entrada para carga de datos
public void load(LeadQueryPlan plan) {
if (plan == null) { return; }
loadDelegadoComercialUsers(plan);
}
private void loadDelegadoComercialUsers(LeadQueryPlan plan) {
if (!plan.needDelegadoComercialUsers || plan.delegationIdsForDelegadoComercial.isEmpty()) {
return;
}
IDelegationUsersSelector selector =
(IDelegationUsersSelector) Application.Selector.newInstance(DelegationUser__c.SObjectType);
this.delegadoComercialUsersByDelegationId.putAll(
selector.selectDelegadoComercialUserIdsByDelegationIds(plan.delegationIdsForDelegadoComercial)
);
}
public Set<Id> getDelegadoComercialUsers(Id delegationId) {
return this.delegadoComercialUsersByDelegationId.containsKey(delegationId)
? this.delegadoComercialUsersByDelegationId.get(delegationId)
: new Set<Id>();
}
}Responsabilidades:
- Ser el único ejecutor de SOQL en el trigger context
- Cargar datos solo si alguna Feature los necesitó (evaluando flags del QueryPlan)
- Consolidar IDs de múltiples features en una sola query
4. [Object]Feature (clase abstracta base)
Clase base de todas las funcionalidades del trigger. Define el contrato que deben cumplir:
public abstract class LeadFeature {
// Opcional: Declara qué datos necesita. No hacer SOQL aquí.
public virtual void collect(LeadQueryPlan plan, LeadContext ctx) { }
// Obligatorio: Ejecuta la lógica de negocio
public abstract void run(LeadContext ctx, LeadDataset dataset, fflib_ISObjectUnitOfWork uow);
public String getName() {
return String.valueOf(this).split(':')[0];
}
}collect()es opcional (virtual vacío). Solo se sobreescribe si la Feature necesita cargar datos del exterior.run()es obligatorio (abstract). Aquí va toda la lógica de negocio.- En eventos BEFORE, el parámetro
uowllegará comonull.
Flujo de ejecución completo
Diagrama visual del flujo de datos
El siguiente diagrama muestra cómo los datos fluyen horizontalmente a través de todas las features durante COLLECT, se consolidan en una sola pasada vertical hacia la base de datos durante LOAD, y luego se distribuyen de vuelta en memoria durante RUN:
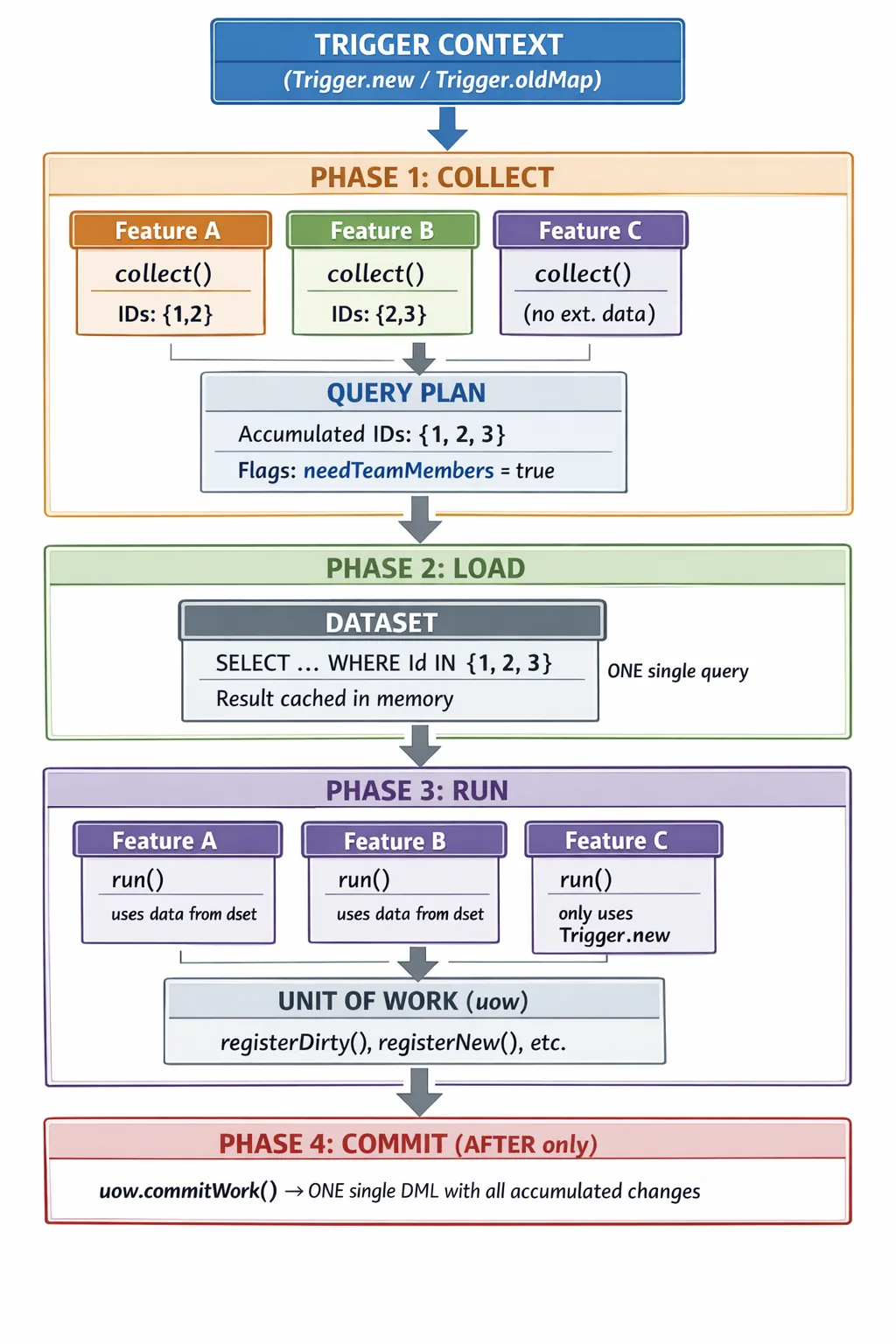
Puntos clave del diagrama:
- Las features declaran datos en paralelo durante COLLECT, sin ejecutar queries.
- El QueryPlan deduplica IDs automáticamente (2 + 3 = 3).
- El Dataset hace una sola query a la base de datos con todos los IDs consolidados.
- En RUN, todas las features acceden a los mismos datos en memoria (sin queries adicionales).
- Feature C no necesita datos externos — no participa en COLLECT, pero sí en RUN.
Evento AFTER (con COMMIT)
TriggerHandler.afterUpdate() / afterInsert()
└── executeFeatures(ctx, features)
├── [COLLECT] feature1.collect(plan, ctx) ← sin SOQL
├── [COLLECT] feature2.collect(plan, ctx) ← sin SOQL
├── [LOAD] dataset.load(plan) ← UNA SOLA pasada de SOQL
├── [RUN] feature1.run(ctx, dataset, uow) ← datos ya en memoria
├── [RUN] feature2.run(ctx, dataset, uow) ← datos ya en memoria
└── [COMMIT] uow.commitWork() ← DML transaccionalEvento BEFORE (sin COMMIT)
TriggerHandler.beforeInsert() / beforeUpdate()
└── executeFeatures(ctx, features)
├── [COLLECT] feature1.collect(plan, ctx) ← sin SOQL
├── [COLLECT] feature2.collect(plan, ctx) ← sin SOQL
├── [LOAD] dataset.load(plan) ← queries SOQL
├── [RUN] feature1.run(ctx, dataset, null) ← uow = null
└── [RUN] feature2.run(ctx, dataset, null) ← modificar registros directamenteCuidado con
beforeInsert: En este evento, los registros deTrigger.newno tienen ID (Idesnull). Si tu feature intenta acumular IDs de los propios registros entrantes en el QueryPlan (por ejemplo,plan.requireRelatedData(newRecord.Id)), estos seránnully la query no devolverá resultados. EnbeforeInsert, el QueryPlan solo debe acumular IDs de campos relacionales que ya tengan valor (comoAccountId,OwnerId, o campos lookup que vengan pre-populados). Este es un error clásico que un desarrollador nuevo cometerá al usar el framework.
Implementación del orquestador en el TriggerHandler
public class LeadTriggerHandler extends TriggerHandler {
public override void afterUpdate() {
executeFeatures(
new LeadContext((List<Lead>) Trigger.new, (Map<Id, Lead>) Trigger.oldMap, TriggerOperation.AFTER_UPDATE),
getAfterUpdateFeatures()
);
}
public override void beforeInsert() {
executeFeatures(
new LeadContext((List<Lead>) Trigger.new, null, TriggerOperation.BEFORE_INSERT),
getBeforeInsertFeatures()
);
}
private List<LeadFeature> getAfterUpdateFeatures() {
return new List<LeadFeature>{ new PromoNameNotificationFeature() };
}
private List<LeadFeature> getBeforeInsertFeatures() {
return new List<LeadFeature>{ };
}
private void executeFeatures(LeadContext ctx, List<LeadFeature> features) {
LeadQueryPlan plan = new LeadQueryPlan();
LeadDataset dataset = new LeadDataset();
for (LeadFeature feature : features) { feature.collect(plan, ctx); }
dataset.load(plan);
Boolean isAfterEvent = ctx.operationType == TriggerOperation.AFTER_UPDATE
|| ctx.operationType == TriggerOperation.AFTER_INSERT
|| ctx.operationType == TriggerOperation.AFTER_DELETE;
fflib_ISObjectUnitOfWork uow = isAfterEvent ? Application.UnitOfWork.newInstance() : null;
for (LeadFeature feature : features) {
try {
feature.run(ctx, dataset, uow);
} catch (Exception e) {
Logger.error(new LogMessage('Error in feature {0}: {1}', feature.getName(), e.getMessage()))
.setExceptionDetails(e).addTags(LOGGER_TAGS);
}
}
if (uow != null) {
try { uow.commitWork(); }
catch (Exception ex) { Logger.error('Error in commitWork').setExceptionDetails(ex).addTags(LOGGER_TAGS); }
}
}
}Ejemplo práctico: ClosedWonFollowUpFeature
Este ejemplo usa Opportunity para mostrar que el patrón es válido para cualquier SObject. La feature crea una Task de seguimiento para cada miembro del equipo de cuenta (AccountTeamMember) cuando una oportunidad pasa a estado “Closed Won”.
Este caso de uso muestra con claridad el valor del QueryPlan: si en un mismo trigger se actualizan 50 oportunidades de 5 cuentas distintas, el patrón garantiza que se ejecute una sola query para cargar todos los AccountTeamMember, en lugar de hasta 50 queries individuales.
Impacto real en Governor Limits
Escenario: 200 Opportunities actualizadas a “Closed Won”, pertenecientes a 15 Accounts distintas. Dos features necesitan consultar
AccountTeamMember.
| Métrica | Sin Query Plan | Con Query Plan | Diferencia |
|---|---|---|---|
| SOQL queries ejecutadas | 400 (200 × 2 features) | 1 | -99.75% |
| Registros consultados | Duplicados en cada feature | Una sola carga compartida | Sin duplicados |
| ¿Excede el límite de 100 SOQL? | Sí — System.LimitException | No — usa 1 de 100 | Transacción segura |
| DML statements | Dispersos en cada feature | 1 (uow.commitWork()) | Atómico y consolidado |
Resultado: de 400 queries que rompen la transacción a 1 sola query que consume el 1% del governor limit. Este es el valor principal del patrón — y escala linealmente: más features compartiendo datos = mayor ahorro.
Clase completa
public class ClosedWonFollowUpFeature extends OpportunityFeature {
// Estado interno entre collect() y run()
private List<Opportunity> closedOpportunities = new List<Opportunity>();
// FASE COLLECT: identifica qué oportunidades acaban de cerrarse
// y declara qué AccountIds necesitará cargar el Dataset
public override void collect(OpportunityQueryPlan plan, OpportunityContext ctx) {
for (Opportunity newOpp : ctx.getOpportunities()) {
Opportunity oldOpp = ctx.getOldOpportunity(newOpp.Id);
if (justClosedWon(newOpp, oldOpp)) {
closedOpportunities.add(newOpp);
plan.requireAccountTeamMembers(newOpp.AccountId);
}
}
}
// FASE RUN: usa los datos ya cargados en memoria para crear las tareas
public override void run(OpportunityContext ctx, OpportunityDataset dataset, fflib_ISObjectUnitOfWork uow) {
for (Opportunity opp : closedOpportunities) {
List<AccountTeamMember> teamMembers = dataset.getAccountTeamMembers(opp.AccountId);
for (AccountTeamMember member : teamMembers) {
uow.registerNew(new Task(
Subject = 'Seguimiento post-cierre: ' + opp.Name,
OwnerId = member.UserId,
WhatId = opp.Id,
ActivityDate = Date.today().addDays(7),
Priority = 'Normal',
Status = 'Not Started'
));
}
}
}
private Boolean justClosedWon(Opportunity newOpp, Opportunity oldOpp) {
return newOpp.StageName == 'Closed Won'
&& (oldOpp == null || oldOpp.StageName != 'Closed Won');
}
}OpportunityQueryPlan y OpportunityDataset del ejemplo
Para entender la “magia” completa, aquí están las clases que soportan este ejemplo:
// OpportunityQueryPlan: acumula las necesidades de TODAS las features
public class OpportunityQueryPlan {
public Boolean needAccountTeamMembers { get; set; }
public Set<Id> accountIdsForTeamMembers { get; private set; }
public OpportunityQueryPlan() {
this.needAccountTeamMembers = false;
this.accountIdsForTeamMembers = new Set<Id>();
}
// Si 3 features distintas llaman a este método con IDs diferentes,
// TODOS se acumulan en un solo Set → una sola query
public OpportunityQueryPlan requireAccountTeamMembers(Id accountId) {
this.needAccountTeamMembers = true;
if (accountId != null) { this.accountIdsForTeamMembers.add(accountId); }
return this;
}
}// OpportunityDataset: ejecuta UNA sola query con TODOS los IDs acumulados
public inherited sharing class OpportunityDataset {
private Map<Id, List<AccountTeamMember>> teamMembersByAccountId;
public OpportunityDataset() {
this.teamMembersByAccountId = new Map<Id, List<AccountTeamMember>>();
}
public void load(OpportunityQueryPlan plan) {
if (plan == null) { return; }
loadAccountTeamMembers(plan);
}
private void loadAccountTeamMembers(OpportunityQueryPlan plan) {
if (!plan.needAccountTeamMembers || plan.accountIdsForTeamMembers.isEmpty()) {
return;
}
// UNA SOLA QUERY para todos los AccountIds de todas las features
for (AccountTeamMember atm : [
SELECT Id, UserId, AccountId, TeamMemberRole
FROM AccountTeamMember
WHERE AccountId IN :plan.accountIdsForTeamMembers
]) {
if (!this.teamMembersByAccountId.containsKey(atm.AccountId)) {
this.teamMembersByAccountId.put(atm.AccountId, new List<AccountTeamMember>());
}
this.teamMembersByAccountId.get(atm.AccountId).add(atm);
}
}
public List<AccountTeamMember> getAccountTeamMembers(Id accountId) {
return this.teamMembersByAccountId.containsKey(accountId)
? this.teamMembersByAccountId.get(accountId)
: new List<AccountTeamMember>();
}
}¿Por qué este ejemplo ilustra bien el patrón?
- COLLECT no hace SOQL: solo examina los registros del trigger y acumula
AccountIds en el plan. - LOAD consolida queries: si 50 oportunidades pertenecen a 5 cuentas, el
DatasetejecutaSELECT ... WHERE AccountId IN (5 IDs)una única vez. - RUN trabaja en memoria: usa
dataset.getAccountTeamMembers(id)sin tocar la base de datos. - COMMIT es transaccional: todas las
Taskse insertan juntas en un solo DML al final.
Cómo agregar una nueva Feature
¿No es demasiado boilerplate? Depende del tipo de feature. Si tu nueva feature no necesita datos externos (solo opera sobre
Trigger.new), no tocas ni QueryPlan ni Dataset — solo creas la clase Feature y la registras en el Handler (pasos 1 y 2). El paso 3 solo aplica cuando necesitas cargar datos adicionales. Sí, hay más clases que en un handler monolítico. Pero cada clase tiene una responsabilidad única, es testeable en aislamiento y un desarrollador nuevo puede entender qué hace una Feature leyendo solo su clase, sin navegar 500 líneas de un Handler gigantesco.
Paso 1: Crear la clase
public class MiNuevaFeature extends LeadFeature {
public override void collect(LeadQueryPlan plan, LeadContext ctx) {
Set<Id> ids = new Set<Id>();
for (Lead lead : ctx.getLeads()) {
if (miCondicion(lead, ctx.getOldLead(lead.Id))) { ids.add(lead.AssignedDelegation__c); }
}
if (!ids.isEmpty()) { plan.requireDelegadoComercialUsers(ids); }
}
public override void run(LeadContext ctx, LeadDataset dataset, fflib_ISObjectUnitOfWork uow) {
for (Lead lead : ctx.getLeads()) {
// Si es AFTER: uow.registerDirty(...)
// Si es BEFORE: lead.Campo__c = valor;
}
}
}Paso 2: Registrar en el TriggerHandler
private List<LeadFeature> getAfterUpdateFeatures() {
return new List<LeadFeature>{
new PromoNameNotificationFeature(),
new MiNuevaFeature() // Añadir aquí
};
}Paso 3: Ampliar QueryPlan y Dataset (si necesitas nuevos datos)
En [Object]QueryPlan:
public Boolean needMisDatos { get; set; }
public Set<Id> idsParaMisDatos { get; private set; }
public LeadQueryPlan requireMisDatos(Set<Id> ids) {
this.needMisDatos = true;
if (ids != null) { this.idsParaMisDatos.addAll(ids); }
return this;
}En [Object]Dataset:
private void loadMisDatos(LeadQueryPlan plan) {
if (!plan.needMisDatos || plan.idsParaMisDatos.isEmpty()) { return; }
IMiObjetoSelector selector = (IMiObjetoSelector) Application.Selector.newInstance(MiObjeto__c.SObjectType);
for (MiObjeto__c obj : selector.selectByIds(plan.idsParaMisDatos)) {
this.misDatos.put(obj.Id, obj);
}
}Beneficios del patrón
| Problema anterior | Solución con Query Plan |
|---|---|
| Cada feature hacía su propio SOQL | Un único punto de carga (Dataset) |
| SOQL duplicados entre features | Acumulación de IDs → una sola query |
| Lógica entremezclada con queries | Separación clara por fases |
| Difícil de testear en aislamiento | Cada Feature testeable con mocks de Context y Dataset |
| DML disperso en todo el trigger | Un solo uow.commitWork() al final |
| Trigger monolítico difícil de extender | Agregar Feature = crear una clase, sin tocar código existente |
Consideraciones de escalabilidad
¿Y si tengo 50 features en un solo objeto?
Si un SObject como Account tiene 50 procesos de negocio distintos, el QueryPlan podría crecer a decenas de flags y métodos require. Esto es una señal de que el objeto tiene demasiada responsabilidad acumulada. Antes de preocuparte por el tamaño del QueryPlan, evalúa:
- ¿Todas las features pertenecen al trigger? Muchas veces, lógica que está en un trigger debería ser un Platform Event, un Flow o un Queueable. Migra lo que no sea crítico fuera del contexto síncrono.
- Agrupa por dominio funcional: Si el QueryPlan crece mucho, puedes agrupar datos relacionados usando inner classes o composición:
plan.billing().requireInvoices(ids),plan.team().requireMembers(ids). Cada grupo encapsula su propio conjunto de flags. - En la práctica, la mayoría de SObjects tienen entre 5 y 15 features por evento de trigger. El QueryPlan se mantiene legible y manejable a esa escala.
Consumo de Heap Size
El Dataset mantiene una sola copia de los datos en memoria, compartida entre todas las Features. Esto es más eficiente que el enfoque sin patrón donde cada feature almacena su propia copia del resultado.
Sin embargo, ten en cuenta estos límites para transacciones masivas (200 registros):
- Heap Size: 6 MB en contexto síncrono, 12 MB en asíncrono.
- Mitigaciones: limita los campos en el SELECT del Selector (solo los necesarios), usa queries con LIMIT si el caso de uso lo permite, y en casos extremos considera
Database.executeBatchpara chunk processing. - Regla general: el peor caso de heap con este patrón es igual o menor que sin él, porque la consolidación de queries elimina datos duplicados en memoria.
Query Plan vs fflib Selector Layer
Si ya usas fflib, probablemente te preguntes: “¿No resuelve esto el Selector Layer?” La respuesta es que Query Plan no reemplaza los Selectors — los orquesta.
| Aspecto | fflib Selector Layer | Query Plan Architecture |
|---|---|---|
| Quién decide qué cargar | Cada consumidor llama al Selector cuando quiere | Las Features declaran necesidades; el Dataset carga todo junto |
| Momento de la query | Disperso (cada Service o Domain llama por su cuenta) | Consolidado (una sola fase LOAD antes de ejecutar lógica) |
| Deduplicación de IDs | No automática (si 3 servicios piden los mismos IDs, son 3 queries) | Automática (el QueryPlan acumula IDs únicos en un Set) |
| Scope | Genérico para toda la aplicación | Específico para el contexto de un Trigger |
| Quién ejecuta la query | El Selector directamente | El Dataset llama al Selector internamente |
La frase clave: fflib Selectors te dicen CÓMO hacer la query (qué campos, qué filtros, qué orden). El QueryPlan te dice CUÁNDO y CON QUÉ datos hacerla, consolidando múltiples consumidores en una sola ejecución. De hecho, si miras el código del Dataset, verás que internamente usa los fflib Selectors:
// El Dataset USA el Selector de fflib — no lo reemplaza
IDelegationUsersSelector selector =
(IDelegationUsersSelector) Application.Selector.newInstance(DelegationUser__c.SObjectType);Estructura de archivos
force-app/main/default/classes/[Object]/
├── Context/
│ ├── [Object]Context.cls
│ └── [Object]ContextTest.cls
├── QueryPlan/
│ ├── [Object]QueryPlan.cls
│ └── [Object]QueryPlanTest.cls
├── Dataset/
│ └── [Object]Dataset.cls
├── Feature/
│ ├── [Object]Feature.cls
│ ├── MiFeature1.cls
│ └── MiFeature1Test.cls
└── TriggerHandler/
└── [Object]TriggerHandler.clsReglas del patrón (obligatorias)
- SOQL solo en
[Object]Dataset— Ninguna Feature, Context ni TriggerHandler puede hacer queries directas. - DML solo vía UnitOfWork — En eventos AFTER, registrar en
uow. Nunca DML directo en Features. collect()es read-only — Solo declara necesidades al plan, no modifica registros ni hace SOQL.- Estado interno de la Feature — Si una Feature guarda estado entre
collect()yrun(), debe ser un campo de instancia privado. - No usar
Trigger.newdirectamente en Features — Usar siemprectx.getLeads()o el equivalente tipado. - Una Feature = una responsabilidad — Si una Feature necesita hacer más de una cosa, dividirla en dos.
- En eventos BEFORE,
uowes null — Comprobar siuow != nullantes de usarlo, o modificar registros directamente en el contexto.
Bases teóricas de la arquitectura
Esta arquitectura no surge de cero. Es una composición deliberada de cuatro patrones bien establecidos, cada uno resolviendo una dimensión distinta del problema.
1. Template Method — El esqueleto del ciclo de vida
Fuente: Design Patterns: Elements of Reusable Object-Oriented Software — Gang of Four (1994).
Propósito original: Definir el esqueleto de un algoritmo en una clase abstracta, delegando pasos concretos a las subclases, sin que estas puedan alterar la estructura general del algoritmo.
Cómo se aplica aquí:
La clase abstracta [Object]Feature define el ciclo de vida obligatorio de cualquier funcionalidad del trigger: primero collect(), después run(). Este orden lo controla el orquestador (executeFeatures), no cada Feature. Las subclases concretas solo implementan los pasos específicos, sin poder saltarse ni reordenar las fases.
[Object]Feature (abstracta)
├── collect() → hook opcional (virtual vacío por defecto)
└── run() → hook obligatorio (abstract, sin implementación)
PromoNameNotificationFeature (concreta)
├── collect() → declara qué delegaciones necesita
└── run() → envía notificaciones usando datos pre-cargadosSin este patrón, cada desarrollador podría inventar su propia convención para estructurar una feature, rompiendo la consistencia del framework.
2. Strategy — La intercambiabilidad de Features
Fuente: Design Patterns: Elements of Reusable Object-Oriented Software — Gang of Four (1994).
Propósito original: Definir una familia de algoritmos, encapsular cada uno en una clase separada e intercambiarlos sin modificar el código del cliente que los usa.
Cómo se aplica aquí:
El TriggerHandler no contiene lógica de negocio rígida. En su lugar, delega en una lista de Features seleccionable por evento. Cada evento tiene su propia lista de “estrategias” activas (getAfterUpdateFeatures(), getBeforeInsertFeatures(), etc.).
// El TriggerHandler solo itera sobre la interfaz común
for (LeadFeature feature : features) {
feature.collect(plan, ctx); // no sabe qué hace cada feature concreta
}Esto permite añadir, quitar o reemplazar una Feature sin tocar nada del orquestador. La extensibilidad es su principal aportación: nueva funcionalidad = nueva clase, sin modificar código existente (principio Open/Closed).
3. DataLoader — La eficiencia del QueryPlan
Fuente: Facebook Engineering, 2010. Publicado como librería open source en 2015.
Propósito original: Resolver el problema N+1 de queries en aplicaciones con múltiples consumidores de datos independientes. En lugar de que cada consumidor haga su propia query, DataLoader acumula todas las claves solicitadas en un solo “tick” y las resuelve en una única llamada al backend (batching).
El problema N+1 que resuelve:
// SIN DataLoader: N consumidores = N queries
feature1 → SELECT ... WHERE DelegationId__c = 'a'
feature2 → SELECT ... WHERE DelegationId__c = 'b'
feature3 → SELECT ... WHERE DelegationId__c = 'a' ← duplicada!
// CON DataLoader (QueryPlan): N consumidores = 1 query
collect() → plan acumula {'a', 'b'} de las 3 features
load() → SELECT ... WHERE DelegationId__c IN ('a', 'b')Mapeado al framework:
| DataLoader (JavaScript) | Query Plan Architecture (Apex) |
|---|---|
dataloader.load(key) | plan.requireXYZ(ids) en collect() |
| Acumulación en el event loop | Acumulación en la fase COLLECT |
batchLoadFn(keys[]) | dataset.load(plan) |
dataloader.get(key) | dataset.getXYZ(id) en run() |
| Caché por request | Dataset en memoria por transacción |
Este es el patrón más crítico de la arquitectura. Es la razón de existir del QueryPlan y el Dataset: separar el momento en que se declara la necesidad del momento en que se resuelve, permitiendo consolidación automática entre todas las Features.
4. Unit of Work — La consolidación del DML
Fuente: Patterns of Enterprise Application Architecture — Martin Fowler, 2002. Implementación en Salesforce: fflib-apex-common (Apex Enterprise Patterns).
Propósito original: Mantener un registro de todos los objetos afectados por una transacción de negocio y coordinar la escritura de cambios al finalizar, en lugar de hacer operaciones de base de datos de forma dispersa durante la transacción.
Cómo se aplica aquí:
Durante la fase RUN, ninguna Feature ejecuta DML directamente. En su lugar, registra las operaciones en el UnitOfWork:
// Feature registra, no ejecuta
uow.registerDirty(lead); // UPDATE pendiente
uow.registerNew(event); // INSERT pendiente
uow.registerPublishAfterSuccessTransaction(platformEvent); // PUBLISH pendiente
// Solo al final del executeFeatures, se materializa todo:
uow.commitWork(); // UN solo DML con todos los cambios acumuladosEsto garantiza que toda la transacción sea atómica: o se persiste todo correctamente o no se persiste nada. Además minimiza el número de operaciones DML consumidas de los governor limits de Salesforce.
Unit of Work complementa al DataLoader pattern: DataLoader consolida las lecturas (SOQL), Unit of Work consolida las escrituras (DML). Juntos, garantizan el mínimo consumo posible de governor limits en toda la ejecución.
Mapa de correspondencia: patrón ↔ componente
| Patrón | Componente en el framework | Qué resuelve |
|---|---|---|
| Template Method | [Object]Feature (abstracta) | Ciclo de vida uniforme de todas las Features |
| Strategy | Listas get[Evento]Features() | Extensibilidad sin modificar el orquestador |
| DataLoader | [Object]QueryPlan + [Object]Dataset | Consolidación de SOQL entre múltiples Features |
| Unit of Work | fflib_ISObjectUnitOfWork en executeFeatures | Consolidación de DML en una sola transacción |
Artículos Relacionados
 Salesforce
Salesforce Bulk DML Service Pattern: Operaciones DML Parciales en Salesforce
Documentación técnica completa del framework Bulk DML Service Pattern para Salesforce. Aprende a realizar operaciones DML resilientes con éxito parcial usando una API familiar estilo Unit of Work.
 Salesforce
Salesforce Arquitectura Salesforce con FFLib: Patrones Enterprise
Guía completa sobre la implementación de patrones arquitectónicos enterprise en Salesforce utilizando FFLib. Incluye Domain Layer, Selector Layer, Service Layer y Unit of Work.
 Salesforce Destacado
Salesforce Destacado CI/CD para Salesforce: Automatización de Despliegues
Implementación completa de pipelines CI/CD para Salesforce usando GitHub Actions, SFDX CLI y Scratch Orgs. Incluye mejores prácticas y troubleshooting.