Query Plan Architecture : Pattern pour les Triggers Apex
Découvrez comment structurer des triggers complexes dans Salesforce avec le pattern Query Plan Architecture. Séparez la logique en 4 phases (Collect, Load, Run, Commit) pour éliminer les SOQL dupliqués, respecter les governor limits et faciliter les tests.
Voir le code source complet sur GitHub : salesforce-query-plan-architecture
Qu’est-ce que ce pattern ?
Query Plan Architecture est un pattern de conception pour structurer la logique interne de tout Trigger Handler dans Salesforce Apex. Il s’applique à tout SObject et tout événement de trigger (beforeInsert, beforeUpdate, afterInsert, afterUpdate, etc.).
Son objectif est de résoudre le problème classique des triggers complexes : de multiples fonctionnalités effectuant chacune leurs propres requêtes SOQL indépendantes, générant un code difficile à maintenir, des requêtes dupliquées et le risque de dépasser les governor limits.
Le pattern divise l’exécution de chaque “feature” (fonctionnalité) en 4 phases clairement différenciées, appliquant le principe de séparation des responsabilités :
| Phase | Responsable | Ce qu’elle fait |
|---|---|---|
| 1. COLLECT | TriggerFeature.collect() | Déclare les données nécessaires (sans faire de requêtes) |
| 2. LOAD | TriggerDataset.load() | Exécute toutes les requêtes SOQL en un seul passage |
| 3. RUN | TriggerFeature.run() | Exécute la logique métier avec les données déjà chargées |
| 4. COMMIT | fflib_ISObjectUnitOfWork | Persiste tous les changements DML (uniquement dans les événements AFTER) |
Note importante sur BEFORE vs AFTER :
- Dans les événements BEFORE (
beforeInsert,beforeUpdate) : les phases COLLECT, LOAD et RUN s’appliquent de la même façon. La phase COMMIT ne s’applique pas car les enregistrements n’ont pas encore d’ID et Salesforce gère la persistance à la fin du contexte before.- Dans les événements AFTER (
afterInsert,afterUpdate) : toutes les phases s’appliquent, y compris COMMIT avecuow.commitWork().
Composants du pattern
Chaque SObject implémentant ce pattern aura son propre ensemble de classes avec le préfixe de l’objet. Les exemples utilisent Lead comme référence, mais le pattern est identique pour tout autre objet.
1. [Object]Context
Encapsule les données du trigger (Trigger.new, Trigger.oldMap, opération) et fournit des accesseurs typés et des helpers métier sans exécuter aucune requête SOQL.
// Exemple générique
public class LeadContext extends BaseTriggerContext {
public LeadContext(List<Lead> newList, Map<Id, Lead> oldMap, TriggerOperation op) {
super(newList, oldMap, op);
}
public List<Lead> getLeads() { return (List<Lead>) this.newList; }
public Lead getOldLead(Id id) { return (Lead) this.oldMap?.get(id); }
// Helpers métier spécifiques à l'objet...
public Boolean statusChanged(Lead newLead, Lead oldLead) { ... }
}Responsabilités :
- Fournir un accès typé à
Trigger.newetTrigger.oldMap - Exposer l’opération du trigger (
BEFORE_INSERT,AFTER_UPDATE, etc.) - Contenir des helpers métier réutilisables entre Features
- Ne jamais faire de SOQL
Note sur
BaseTriggerContext: En étendant cette classe de base, le Context gère déjà en interne le casting deTrigger.newetTrigger.oldMapvers le type correct. Cela évite à chaque Feature de devoir faire son propre casting manuel, réduisant les erreurs et le code répétitif. Les méthodes typées (getLeads(),getOldLead()) sont de simples wrappers sur des données déjà castées dans le constructeur.
2. [Object]QueryPlan
Agit comme un objet de configuration accumulateur (“liste de courses”). Les Features le remplissent durant la phase COLLECT pour déclarer quelles données elles auront besoin dans la phase RUN. Il n’exécute aucune requête.
// Exemple générique
public class LeadQueryPlan {
public Boolean needDelegadoComercialUsers { get; set; }
public Set<Id> delegationIdsForDelegadoComercial { get; private set; }
public LeadQueryPlan() {
this.needDelegadoComercialUsers = false;
this.delegationIdsForDelegadoComercial = new Set<Id>();
}
// Méthode fluent : permet le chaînage et accumule les IDs de plusieurs features
public LeadQueryPlan requireDelegadoComercialUsers(Set<Id> ids) {
this.needDelegadoComercialUsers = true;
if (ids != null) { this.delegationIdsForDelegadoComercial.addAll(ids); }
return this;
}
// Utilitaire de débogage
public String getSummary() { ... }
}Responsabilités :
- Accumuler les IDs et flags de toutes les Features en un seul passage
- Éviter les requêtes dupliquées (si 5 Features ont besoin des mêmes données, le plan ne les charge qu’une fois)
- Ne jamais faire de SOQL
3. [Object]Dataset
C’est la SEULE classe qui exécute des requêtes SOQL dans le contexte du trigger. Elle reçoit le QueryPlan déjà rempli, exécute les requêtes minimales nécessaires et met en cache les résultats pour le reste de la transaction.
// Exemple générique
public inherited sharing class LeadDataset {
public Map<Id, Set<Id>> delegadoComercialUsersByDelegationId { get; private set; }
public LeadDataset() {
this.delegadoComercialUsersByDelegationId = new Map<Id, Set<Id>>();
}
// Point d'entrée unique pour le chargement des données
public void load(LeadQueryPlan plan) {
if (plan == null) { return; }
loadDelegadoComercialUsers(plan);
}
private void loadDelegadoComercialUsers(LeadQueryPlan plan) {
if (!plan.needDelegadoComercialUsers || plan.delegationIdsForDelegadoComercial.isEmpty()) {
return;
}
IDelegationUsersSelector selector =
(IDelegationUsersSelector) Application.Selector.newInstance(DelegationUser__c.SObjectType);
this.delegadoComercialUsersByDelegationId.putAll(
selector.selectDelegadoComercialUserIdsByDelegationIds(plan.delegationIdsForDelegadoComercial)
);
}
public Set<Id> getDelegadoComercialUsers(Id delegationId) {
return this.delegadoComercialUsersByDelegationId.containsKey(delegationId)
? this.delegadoComercialUsersByDelegationId.get(delegationId)
: new Set<Id>();
}
}Responsabilités :
- Être le seul exécuteur de SOQL dans le contexte du trigger
- Charger les données uniquement si une Feature en a besoin (en évaluant les flags du QueryPlan)
- Consolider les IDs de plusieurs features en une seule requête
4. [Object]Feature (classe de base abstraite)
Classe de base de toutes les fonctionnalités du trigger. Définit le contrat qu’elles doivent respecter :
public abstract class LeadFeature {
// Optionnel : Déclare les données nécessaires. Ne pas faire de SOQL ici.
public virtual void collect(LeadQueryPlan plan, LeadContext ctx) { }
// Obligatoire : Exécute la logique métier
public abstract void run(LeadContext ctx, LeadDataset dataset, fflib_ISObjectUnitOfWork uow);
public String getName() {
return String.valueOf(this).split(':')[0];
}
}collect()est optionnel (virtual vide). À surcharger uniquement si la Feature a besoin de charger des données externes.run()est obligatoire (abstract). Toute la logique métier va ici.- Dans les événements BEFORE, le paramètre
uowarrivera commenull.
Flux d’exécution complet
Diagramme visuel du flux de données
Le diagramme suivant montre comment les données circulent horizontalement à travers toutes les features pendant COLLECT, se consolident en un seul passage vertical vers la base de données pendant LOAD, puis se redistribuent en mémoire pendant RUN :
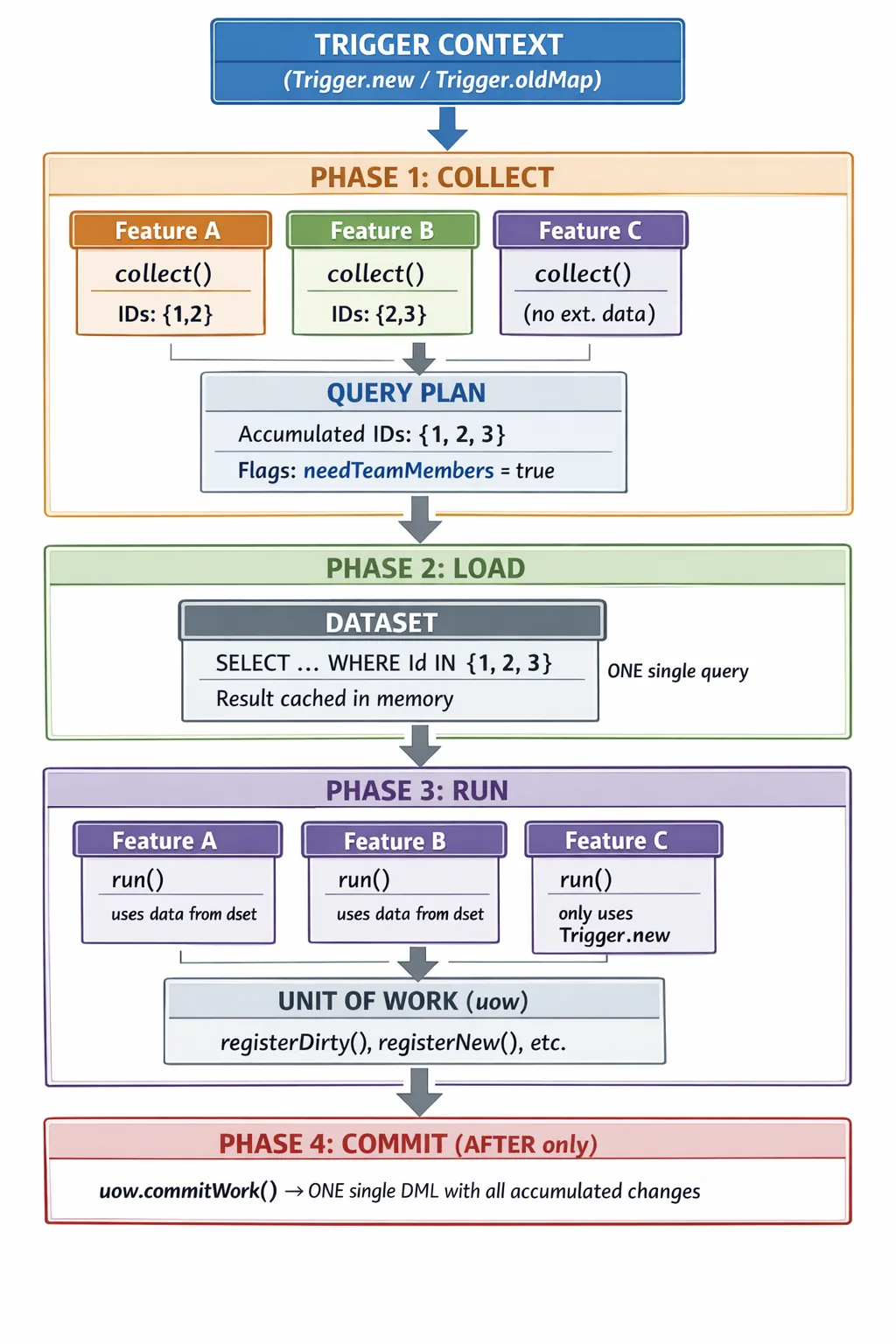
Points clés du diagramme :
- Les features déclarent leurs besoins en données en parallèle pendant COLLECT, sans exécuter de requêtes.
- Le QueryPlan déduplique les IDs automatiquement (2 + 3 = 3).
- Le Dataset effectue une seule requête à la base de données avec tous les IDs consolidés.
- Pendant RUN, toutes les features accèdent aux mêmes données en mémoire (pas de requêtes supplémentaires).
- La Feature C n’a pas besoin de données externes — elle ne participe pas au COLLECT, mais elle participe au RUN.
Événement AFTER (avec COMMIT)
TriggerHandler.afterUpdate() / afterInsert()
└── executeFeatures(ctx, features)
├── [COLLECT] feature1.collect(plan, ctx) ← sans SOQL
├── [COLLECT] feature2.collect(plan, ctx) ← sans SOQL
├── [LOAD] dataset.load(plan) ← UN SEUL passage SOQL
├── [RUN] feature1.run(ctx, dataset, uow) ← données déjà en mémoire
├── [RUN] feature2.run(ctx, dataset, uow) ← données déjà en mémoire
└── [COMMIT] uow.commitWork() ← DML transactionnelÉvénement BEFORE (sans COMMIT)
TriggerHandler.beforeInsert() / beforeUpdate()
└── executeFeatures(ctx, features)
├── [COLLECT] feature1.collect(plan, ctx) ← sans SOQL
├── [COLLECT] feature2.collect(plan, ctx) ← sans SOQL
├── [LOAD] dataset.load(plan) ← requêtes SOQL
├── [RUN] feature1.run(ctx, dataset, null) ← uow = null
└── [RUN] feature2.run(ctx, dataset, null) ← modifier les enregistrements directementAttention avec
beforeInsert: Dans cet événement, les enregistrements deTrigger.newn’ont pas d’ID (Idestnull). Si votre feature essaie d’accumuler les IDs des enregistrements entrants eux-mêmes dans le QueryPlan (par exemple,plan.requireRelatedData(newRecord.Id)), ceux-ci serontnullet la requête ne renverra aucun résultat. DansbeforeInsert, le QueryPlan ne doit accumuler que les IDs de champs relationnels qui ont déjà une valeur (commeAccountId,OwnerId, ou les champs lookup pré-remplis). C’est une erreur classique qu’un développeur junior commettra en utilisant le framework.
Implémentation de l’orchestrateur dans le TriggerHandler
public class LeadTriggerHandler extends TriggerHandler {
public override void afterUpdate() {
executeFeatures(
new LeadContext((List<Lead>) Trigger.new, (Map<Id, Lead>) Trigger.oldMap, TriggerOperation.AFTER_UPDATE),
getAfterUpdateFeatures()
);
}
public override void beforeInsert() {
executeFeatures(
new LeadContext((List<Lead>) Trigger.new, null, TriggerOperation.BEFORE_INSERT),
getBeforeInsertFeatures()
);
}
private List<LeadFeature> getAfterUpdateFeatures() {
return new List<LeadFeature>{ new PromoNameNotificationFeature() };
}
private List<LeadFeature> getBeforeInsertFeatures() {
return new List<LeadFeature>{ };
}
private void executeFeatures(LeadContext ctx, List<LeadFeature> features) {
LeadQueryPlan plan = new LeadQueryPlan();
LeadDataset dataset = new LeadDataset();
for (LeadFeature feature : features) { feature.collect(plan, ctx); }
dataset.load(plan);
Boolean isAfterEvent = ctx.operationType == TriggerOperation.AFTER_UPDATE
|| ctx.operationType == TriggerOperation.AFTER_INSERT
|| ctx.operationType == TriggerOperation.AFTER_DELETE;
fflib_ISObjectUnitOfWork uow = isAfterEvent ? Application.UnitOfWork.newInstance() : null;
for (LeadFeature feature : features) {
try {
feature.run(ctx, dataset, uow);
} catch (Exception e) {
Logger.error(new LogMessage('Error in feature {0}: {1}', feature.getName(), e.getMessage()))
.setExceptionDetails(e).addTags(LOGGER_TAGS);
}
}
if (uow != null) {
try { uow.commitWork(); }
catch (Exception ex) { Logger.error('Error in commitWork').setExceptionDetails(ex).addTags(LOGGER_TAGS); }
}
}
}Exemple pratique : ClosedWonFollowUpFeature
Cet exemple utilise Opportunity pour montrer que le pattern est valide pour tout SObject. La feature crée une Task de suivi pour chaque membre de l’équipe de compte (AccountTeamMember) lorsqu’une opportunité passe au stade “Closed Won”.
Ce cas d’usage illustre clairement la valeur du QueryPlan : si 50 opportunités de 5 comptes différents sont mises à jour dans le même trigger, le pattern garantit qu’une seule requête est exécutée pour charger tous les AccountTeamMember, au lieu de jusqu’à 50 requêtes individuelles.
Impact réel sur les Governor Limits
Scénario : 200 Opportunities mises à jour vers “Closed Won”, appartenant à 15 Accounts différents. Deux features doivent interroger
AccountTeamMember.
| Métrique | Sans Query Plan | Avec Query Plan | Différence |
|---|---|---|---|
| Requêtes SOQL exécutées | 400 (200 × 2 features) | 1 | -99,75% |
| Enregistrements interrogés | Dupliqués dans chaque feature | Un seul chargement partagé | Pas de doublons |
| Dépasse la limite de 100 SOQL ? | Oui — System.LimitException | Non — utilise 1 sur 100 | Transaction sécurisée |
| Opérations DML | Dispersées dans chaque feature | 1 (uow.commitWork()) | Atomique et consolidé |
Résultat : de 400 requêtes qui cassent la transaction à 1 seule requête consommant 1% du governor limit. C’est la valeur principale du pattern — et elle évolue linéairement : plus de features partageant des données = plus d’économies.
Classe complète
public class ClosedWonFollowUpFeature extends OpportunityFeature {
// État interne entre collect() et run()
private List<Opportunity> closedOpportunities = new List<Opportunity>();
// PHASE COLLECT : identifie quelles opportunités viennent de se fermer
// et déclare quels AccountIds le Dataset devra charger
public override void collect(OpportunityQueryPlan plan, OpportunityContext ctx) {
for (Opportunity newOpp : ctx.getOpportunities()) {
Opportunity oldOpp = ctx.getOldOpportunity(newOpp.Id);
if (justClosedWon(newOpp, oldOpp)) {
closedOpportunities.add(newOpp);
plan.requireAccountTeamMembers(newOpp.AccountId);
}
}
}
// PHASE RUN : utilise les données déjà chargées en mémoire pour créer les tâches
public override void run(OpportunityContext ctx, OpportunityDataset dataset, fflib_ISObjectUnitOfWork uow) {
for (Opportunity opp : closedOpportunities) {
List<AccountTeamMember> teamMembers = dataset.getAccountTeamMembers(opp.AccountId);
for (AccountTeamMember member : teamMembers) {
uow.registerNew(new Task(
Subject = 'Suivi post-clôture : ' + opp.Name,
OwnerId = member.UserId,
WhatId = opp.Id,
ActivityDate = Date.today().addDays(7),
Priority = 'Normal',
Status = 'Not Started'
));
}
}
}
private Boolean justClosedWon(Opportunity newOpp, Opportunity oldOpp) {
return newOpp.StageName == 'Closed Won'
&& (oldOpp == null || oldOpp.StageName != 'Closed Won');
}
}OpportunityQueryPlan et OpportunityDataset de l’exemple
Pour comprendre la “magie” complète, voici les classes qui supportent cet exemple :
// OpportunityQueryPlan : accumule les besoins de TOUTES les features
public class OpportunityQueryPlan {
public Boolean needAccountTeamMembers { get; set; }
public Set<Id> accountIdsForTeamMembers { get; private set; }
public OpportunityQueryPlan() {
this.needAccountTeamMembers = false;
this.accountIdsForTeamMembers = new Set<Id>();
}
// Si 3 features différentes appellent cette méthode avec des IDs différents,
// TOUS sont accumulés dans un seul Set → une seule requête
public OpportunityQueryPlan requireAccountTeamMembers(Id accountId) {
this.needAccountTeamMembers = true;
if (accountId != null) { this.accountIdsForTeamMembers.add(accountId); }
return this;
}
}// OpportunityDataset : exécute UNE SEULE requête avec TOUS les IDs accumulés
public inherited sharing class OpportunityDataset {
private Map<Id, List<AccountTeamMember>> teamMembersByAccountId;
public OpportunityDataset() {
this.teamMembersByAccountId = new Map<Id, List<AccountTeamMember>>();
}
public void load(OpportunityQueryPlan plan) {
if (plan == null) { return; }
loadAccountTeamMembers(plan);
}
private void loadAccountTeamMembers(OpportunityQueryPlan plan) {
if (!plan.needAccountTeamMembers || plan.accountIdsForTeamMembers.isEmpty()) {
return;
}
// UNE SEULE REQUÊTE pour tous les AccountIds de toutes les features
for (AccountTeamMember atm : [
SELECT Id, UserId, AccountId, TeamMemberRole
FROM AccountTeamMember
WHERE AccountId IN :plan.accountIdsForTeamMembers
]) {
if (!this.teamMembersByAccountId.containsKey(atm.AccountId)) {
this.teamMembersByAccountId.put(atm.AccountId, new List<AccountTeamMember>());
}
this.teamMembersByAccountId.get(atm.AccountId).add(atm);
}
}
public List<AccountTeamMember> getAccountTeamMembers(Id accountId) {
return this.teamMembersByAccountId.containsKey(accountId)
? this.teamMembersByAccountId.get(accountId)
: new List<AccountTeamMember>();
}
}Pourquoi cet exemple illustre-t-il bien le pattern ?
- COLLECT ne fait pas de SOQL : il examine uniquement les enregistrements du trigger et accumule les
AccountIds dans le plan. - LOAD consolide les requêtes : si 50 opportunités appartiennent à 5 comptes, le
DatasetexécuteSELECT ... WHERE AccountId IN (5 IDs)une seule fois. - RUN travaille en mémoire : utilise
dataset.getAccountTeamMembers(id)sans toucher la base de données. - COMMIT est transactionnel : toutes les
Tasksont insérées ensemble en un seul DML à la fin.
Comment ajouter une nouvelle Feature
N’est-ce pas trop de boilerplate ? Cela dépend du type de feature. Si votre nouvelle feature n’a pas besoin de données externes (elle opère uniquement sur
Trigger.new), vous ne touchez ni le QueryPlan ni le Dataset — vous créez simplement la classe Feature et l’enregistrez dans le Handler (étapes 1 et 2). L’étape 3 ne s’applique que lorsque vous devez charger des données supplémentaires. Oui, il y a plus de classes que dans un handler monolithique. Mais chaque classe a une responsabilité unique, est testable en isolation, et un nouveau développeur peut comprendre ce que fait une Feature en lisant uniquement sa classe, sans parcourir 500 lignes d’un Handler géant.
Étape 1 : Créer la classe
public class MaNouvelleFeature extends LeadFeature {
public override void collect(LeadQueryPlan plan, LeadContext ctx) {
Set<Id> ids = new Set<Id>();
for (Lead lead : ctx.getLeads()) {
if (maCondition(lead, ctx.getOldLead(lead.Id))) { ids.add(lead.AssignedDelegation__c); }
}
if (!ids.isEmpty()) { plan.requireDelegadoComercialUsers(ids); }
}
public override void run(LeadContext ctx, LeadDataset dataset, fflib_ISObjectUnitOfWork uow) {
for (Lead lead : ctx.getLeads()) {
// Si AFTER : uow.registerDirty(...)
// Si BEFORE : lead.MonChamp__c = valeur;
}
}
}Étape 2 : Enregistrer dans le TriggerHandler
private List<LeadFeature> getAfterUpdateFeatures() {
return new List<LeadFeature>{
new PromoNameNotificationFeature(),
new MaNouvelleFeature() // Ajouter ici
};
}Étape 3 : Étendre QueryPlan et Dataset (si vous avez besoin de nouvelles données)
Dans [Object]QueryPlan :
public Boolean needMesDonnees { get; set; }
public Set<Id> idsPourMesDonnees { get; private set; }
public LeadQueryPlan requireMesDonnees(Set<Id> ids) {
this.needMesDonnees = true;
if (ids != null) { this.idsPourMesDonnees.addAll(ids); }
return this;
}Dans [Object]Dataset :
private void loadMesDonnees(LeadQueryPlan plan) {
if (!plan.needMesDonnees || plan.idsPourMesDonnees.isEmpty()) { return; }
IMonObjetSelector selector = (IMonObjetSelector) Application.Selector.newInstance(MonObjet__c.SObjectType);
for (MonObjet__c obj : selector.selectByIds(plan.idsPourMesDonnees)) {
this.mesDonnees.put(obj.Id, obj);
}
}Bénéfices du pattern
| Problème précédent | Solution avec Query Plan |
|---|---|
| Chaque feature faisait son propre SOQL | Un unique point de chargement (Dataset) |
| SOQL dupliqués entre features | Accumulation d’IDs → une seule requête |
| Logique entremêlée avec les requêtes | Séparation claire par phases |
| Difficile à tester en isolation | Chaque Feature testable avec des mocks de Context et Dataset |
| DML dispersé dans tout le trigger | Un seul uow.commitWork() à la fin |
| Trigger monolithique difficile à étendre | Ajouter une Feature = créer une classe, sans toucher le code existant |
Considérations de scalabilité
Et si j’ai 50 features sur un seul objet ?
Si un SObject comme Account a 50 processus métier distincts, le QueryPlan pourrait grossir jusqu’à des dizaines de flags et méthodes require. C’est un signal que l’objet accumule trop de responsabilités. Avant de s’inquiéter de la taille du QueryPlan, évaluez :
- Toutes les features appartiennent-elles au trigger ? Souvent, de la logique qui se trouve dans un trigger devrait être un Platform Event, un Flow ou un Queueable. Migrez ce qui n’est pas critique hors du contexte synchrone.
- Regroupez par domaine fonctionnel : Si le QueryPlan grossit trop, vous pouvez regrouper les données liées en utilisant des inner classes ou la composition :
plan.billing().requireInvoices(ids),plan.team().requireMembers(ids). Chaque groupe encapsule son propre ensemble de flags. - En pratique, la plupart des SObjects ont entre 5 et 15 features par événement de trigger. Le QueryPlan reste lisible et gérable à cette échelle.
Consommation de Heap Size
Le Dataset maintient une seule copie des données en mémoire, partagée entre toutes les Features. C’est plus efficace que l’approche sans pattern où chaque feature stocke sa propre copie du résultat.
Cependant, gardez ces limites en tête pour les transactions massives (200 enregistrements) :
- Heap Size : 6 Mo en contexte synchrone, 12 Mo en asynchrone.
- Atténuations : limitez les champs dans le SELECT du Selector (uniquement les nécessaires), utilisez des requêtes avec LIMIT si le cas d’usage le permet, et dans les cas extrêmes envisagez
Database.executeBatchpour le traitement par lots. - Règle générale : le pire cas de heap avec ce pattern est égal ou inférieur à celui sans pattern, car la consolidation des requêtes élimine les données dupliquées en mémoire.
Query Plan vs fflib Selector Layer
Si vous utilisez déjà fflib, vous vous demandez probablement : “Le Selector Layer ne résout-il pas ça ?” La réponse est que Query Plan ne remplace pas les Selectors — il les orchestre.
| Aspect | fflib Selector Layer | Query Plan Architecture |
|---|---|---|
| Qui décide quoi charger | Chaque consommateur appelle le Selector quand il veut | Les Features déclarent leurs besoins ; le Dataset charge tout ensemble |
| Moment de la requête | Dispersé (chaque Service ou Domain appelle de son côté) | Consolidé (une seule phase LOAD avant d’exécuter la logique) |
| Déduplication d’IDs | Non automatique (si 3 services demandent les mêmes IDs, ce sont 3 requêtes) | Automatique (le QueryPlan accumule les IDs uniques dans un Set) |
| Scope | Générique pour toute l’application | Spécifique au contexte du Trigger |
| Qui exécute la requête | Le Selector directement | Le Dataset appelle le Selector en interne |
Le point clé : les Selectors fflib vous disent COMMENT faire la requête (quels champs, quels filtres, quel ordre). Le QueryPlan vous dit QUAND et AVEC QUELLES données la faire, consolidant plusieurs consommateurs en une seule exécution. En fait, si vous regardez le code du Dataset, vous verrez qu’en interne il utilise les Selectors fflib :
// Le Dataset UTILISE le Selector fflib — il ne le remplace pas
IDelegationUsersSelector selector =
(IDelegationUsersSelector) Application.Selector.newInstance(DelegationUser__c.SObjectType);Structure des fichiers
force-app/main/default/classes/[Object]/
├── Context/
│ ├── [Object]Context.cls
│ └── [Object]ContextTest.cls
├── QueryPlan/
│ ├── [Object]QueryPlan.cls
│ └── [Object]QueryPlanTest.cls
├── Dataset/
│ └── [Object]Dataset.cls
├── Feature/
│ ├── [Object]Feature.cls
│ ├── MaFeature1.cls
│ └── MaFeature1Test.cls
└── TriggerHandler/
└── [Object]TriggerHandler.clsRègles du pattern (obligatoires)
- SOQL uniquement dans
[Object]Dataset— Aucune Feature, Context ou TriggerHandler ne peut faire des requêtes directes. - DML uniquement via UnitOfWork — Dans les événements AFTER, enregistrer dans
uow. Jamais de DML direct dans les Features. collect()est en lecture seule — Il déclare uniquement les besoins au plan, ne modifie pas les enregistrements et ne fait pas de SOQL.- État interne de la Feature — Si une Feature conserve un état entre
collect()etrun(), il doit s’agir d’un champ d’instance privé. - Ne pas utiliser
Trigger.newdirectement dans les Features — Toujours utiliserctx.getLeads()ou l’équivalent typé. - Une Feature = une responsabilité — Si une Feature doit faire plus d’une chose, la diviser en deux.
- Dans les événements BEFORE,
uowest null — Vérifier siuow != nullavant de l’utiliser, ou modifier les enregistrements directement dans le contexte.
Fondements théoriques de l’architecture
Cette architecture n’émerge pas de nulle part. C’est une composition délibérée de quatre patterns bien établis, chacun résolvant une dimension différente du problème.
1. Template Method — Le squelette du cycle de vie
Source : Design Patterns: Elements of Reusable Object-Oriented Software — Gang of Four (1994).
Objectif original : Définir le squelette d’un algorithme dans une classe abstraite, en déléguant les étapes concrètes aux sous-classes, sans leur permettre de modifier la structure générale de l’algorithme.
Comment il s’applique ici :
La classe abstraite [Object]Feature définit le cycle de vie obligatoire de toute fonctionnalité du trigger : d’abord collect(), ensuite run(). Cet ordre est contrôlé par l’orchestrateur (executeFeatures), pas par chaque Feature. Les sous-classes concrètes implémentent uniquement les étapes spécifiques, sans pouvoir sauter ni réordonner les phases.
[Object]Feature (abstraite)
├── collect() → hook optionnel (virtual vide par défaut)
└── run() → hook obligatoire (abstract, sans implémentation)
PromoNameNotificationFeature (concrète)
├── collect() → déclare quelles délégations elle nécessite
└── run() → envoie des notifications en utilisant les données pré-chargéesSans ce pattern, chaque développeur pourrait inventer sa propre convention pour structurer une feature, brisant la cohérence du framework.
2. Strategy — L’interchangeabilité des Features
Source : Design Patterns: Elements of Reusable Object-Oriented Software — Gang of Four (1994).
Objectif original : Définir une famille d’algorithmes, encapsuler chacun dans une classe séparée et les rendre interchangeables sans modifier le code client qui les utilise.
Comment il s’applique ici :
Le TriggerHandler ne contient aucune logique métier rigide. Au lieu de cela, il délègue à une liste de Features sélectionnables par événement. Chaque événement a sa propre liste de “stratégies” actives (getAfterUpdateFeatures(), getBeforeInsertFeatures(), etc.).
// Le TriggerHandler itère uniquement sur l'interface commune
for (LeadFeature feature : features) {
feature.collect(plan, ctx); // ne sait pas ce que fait chaque feature concrète
}Cela permet d’ajouter, retirer ou remplacer une Feature sans rien toucher dans l’orchestrateur. L’extensibilité est sa principale contribution : nouvelle fonctionnalité = nouvelle classe, sans modifier le code existant (principe Open/Closed).
3. DataLoader — L’efficacité du QueryPlan
Source : Facebook Engineering, 2010. Publié en tant que bibliothèque open source en 2015.
Objectif original : Résoudre le problème N+1 de requêtes dans les applications avec plusieurs consommateurs de données indépendants. Au lieu que chaque consommateur fasse sa propre requête, DataLoader accumule toutes les clés demandées en un seul “tick” et les résout en un seul appel au backend (batching).
Le problème N+1 qu’il résout :
// SANS DataLoader : N consommateurs = N requêtes
feature1 → SELECT ... WHERE DelegationId__c = 'a'
feature2 → SELECT ... WHERE DelegationId__c = 'b'
feature3 → SELECT ... WHERE DelegationId__c = 'a' ← dupliquée !
// AVEC DataLoader (QueryPlan) : N consommateurs = 1 requête
collect() → plan accumule {'a', 'b'} des 3 features
load() → SELECT ... WHERE DelegationId__c IN ('a', 'b')Mappé au framework :
| DataLoader (JavaScript) | Query Plan Architecture (Apex) |
|---|---|
dataloader.load(key) | plan.requireXYZ(ids) dans collect() |
| Accumulation dans l’event loop | Accumulation dans la phase COLLECT |
batchLoadFn(keys[]) | dataset.load(plan) |
dataloader.get(key) | dataset.getXYZ(id) dans run() |
| Cache par requête | Dataset en mémoire par transaction |
C’est le pattern le plus critique de l’architecture. C’est la raison d’être du QueryPlan et du Dataset : séparer le moment où le besoin est déclaré du moment où il est résolu, permettant une consolidation automatique entre toutes les Features.
4. Unit of Work — La consolidation du DML
Source : Patterns of Enterprise Application Architecture — Martin Fowler, 2002. Implémentation Salesforce : fflib-apex-common (Apex Enterprise Patterns).
Objectif original : Maintenir un enregistrement de tous les objets affectés par une transaction métier et coordonner l’écriture des changements à la fin, plutôt que de faire des opérations de base de données dispersées tout au long de la transaction.
Comment il s’applique ici :
Durant la phase RUN, aucune Feature n’exécute de DML directement. Au lieu de cela, elle enregistre les opérations dans le UnitOfWork :
// La Feature enregistre, n'exécute pas
uow.registerDirty(lead); // UPDATE en attente
uow.registerNew(event); // INSERT en attente
uow.registerPublishAfterSuccessTransaction(platformEvent); // PUBLISH en attente
// Seulement à la fin de executeFeatures, tout est matérialisé :
uow.commitWork(); // UN seul DML avec tous les changements accumulésCela garantit que toute la transaction est atomique : soit tout est persisté correctement, soit rien ne l’est. Cela minimise également le nombre d’opérations DML consommées depuis les governor limits de Salesforce.
Unit of Work complète le pattern DataLoader : DataLoader consolide les lectures (SOQL), Unit of Work consolide les écritures (DML). Ensemble, ils garantissent la consommation minimale possible de governor limits tout au long de l’exécution.
Carte de correspondance : pattern ↔ composant
| Pattern | Composant dans le framework | Ce qu’il résout |
|---|---|---|
| Template Method | [Object]Feature (abstraite) | Cycle de vie uniforme pour toutes les Features |
| Strategy | Listes get[Événement]Features() | Extensibilité sans modifier l’orchestrateur |
| DataLoader | [Object]QueryPlan + [Object]Dataset | Consolidation SOQL entre plusieurs Features |
| Unit of Work | fflib_ISObjectUnitOfWork dans executeFeatures | Consolidation DML en une seule transaction |
Articles Similaires
 Salesforce
Salesforce Bulk DML Service Pattern: Opérations DML Partielles dans Salesforce
Documentation technique complète du framework Bulk DML Service Pattern pour Salesforce. Apprenez à effectuer des opérations DML résilientes avec un succès partiel en utilisant une API familière de style Unit of Work.
 Salesforce
Salesforce Agentforce : La Révolution de l'IA dans Salesforce
Découvrez Agentforce, la nouvelle plateforme d'agents IA autonomes de Salesforce. Apprenez à créer, configurer et déployer des agents intelligents pour automatiser les processus métier.