Architettura Salesforce con FFLib: Pattern Enterprise
Guida completa all'implementazione dei pattern architetturali enterprise in Salesforce usando FFLib. Include Domain Layer, Selector Layer, Service Layer e Unit of Work.
Introduzione: la mia prospettiva su fflib
Quando si sviluppano applicazioni enterprise su Salesforce, scalabilità e manutenibilità non sono opzionali. Ho visto molti progetti impantanarsi nella loro stessa complessità per mancanza di una struttura chiara. Qui entra in gioco fflib, un’implementazione degli Apex Enterprise Patterns. A mio avviso è uno degli strumenti più potenti per uno sviluppatore Salesforce.
Più che una semplice libreria, fflib fornisce un linguaggio comune e una serie di blueprint per costruire software in modo ordinato. Adotta un approccio a livelli che impone la separazione delle responsabilità (Separation of Concerns), un principio fondamentale spesso trascurato nello sviluppo Apex. In questo articolo condivido la mia esperienza pratica con questa architettura, scomponendone i livelli, i pattern implementati e, soprattutto, l’impatto reale sulla qualità e l’agilità dello sviluppo.
I 4 livelli chiave dell’architettura
La magia di fflib risiede nella sua struttura a strati, in cui ogni livello ha una missione ben precisa. Dimenticatevi classi e trigger monolitici che fanno tutto. Qui il codice è organizzato così:
- Domain Layer: il guardiano della logica di business a livello record. Pensatelo come l’esperto di un oggetto specifico (es.
Account,Lead). - Selector Layer: agisce come repository centralizzato per tutte le query SOQL di un oggetto. È l’unico livello che dovrebbe parlare direttamente al database per leggere i dati.
- Service Layer: il cervello che orchestra le operazioni complesse. Quando un processo di business coinvolge più oggetti o passi, il servizio prende il controllo.
- Unit of Work: gestisce le operazioni DML (insert, update, delete) in modo intelligente, raggruppandole per garantire l’integrità dei dati in una transazione.
Analizziamoli da una prospettiva pratica.
Domain Layer: la prima linea di difesa
Nella mia esperienza, il Domain Layer è la prima linea di difesa contro l’inconsistenza dei dati e la logica di business dispersa. La sua responsabilità è chiara: incapsulare tutte le regole, le validazioni e i comportamenti che appartengono a un singolo record di un oggetto.
Immaginate una regola: “Un Lead non può essere contattato se il suo punteggio è inferiore a 50”. Invece di codificare questa logica in un trigger, in un controller Lightning e in una batch class, la si centralizza in un metodo dentro LeadsDomain.
// LeadsDomain.cls
public class LeadsDomain extends fflib_SObjectDomain {
// Il costruttore riceve la lista di record dal trigger
public LeadsDomain(List<Lead> records) {
super(records);
}
// Metodo invocato prima di un update
public override void onBeforeUpdate(Map<Id, SObject> oldMap) {
for(Lead newLead : (List<Lead>) this.records) {
Lead oldLead = (Lead) oldMap.get(newLead.Id);
// Logica di validazione centralizzata
if (newLead.Status == 'Contacted' && newLead.Score__c < 50) {
newLead.addError('Un Lead con punteggio inferiore a 50 non può essere contattato.');
}
}
}
}Opinione ed esperienza: adottare il Domain Layer è un punto di svolta per i trigger. Ho partecipato a progetti in cui questo pattern è stato decisivo per incapsulare le operazioni DML proprie dell’oggetto e semplificare drasticamente il ciclo di vita del trigger, assicurando un comportamento coerente. Anche se il trigger framework di fflib può sembrare complesso all’inizio, il valore che fornisce centralizzando la logica è enorme e previene il debito tecnico causato da regole duplicate.
Selector Layer: query intelligenti e riutilizzabili
Il Selector Layer è la materializzazione del Repository pattern. La sua missione è costruire ed eseguire query SOQL. Invece di scrivere query direttamente nei servizi o controller, si richiedono i dati al selettore corrispondente.
// ILeadsSelector.cls (Interfaccia)
public interface ILeadsSelector extends fflib_ISObjectSelector {
List<Lead> selectRecentLeadsWithHighValue(Integer limitSize);
}
// LeadsSelector.cls (Implementazione)
public class LeadsSelector extends fflib_SObjectSelector implements ILeadsSelector {
public List<Schema.SObjectField> getSObjectFieldList() {
return new List<Schema.SObjectField>{
Lead.Name, Lead.Company, Lead.Status, Lead.Score__c
};
}
public List<Lead> selectRecentLeadsWithHighValue(Integer limitSize) {
return (List<Lead>) Database.query(
newQueryFactory()
.setCondition('Score__c > 100 AND Status = \'New\'')
.setOrderBy(new fflib_QueryFactory.OrderBy('CreatedDate', 'DESC'))
.setLimit(limitSize)
.toSOQL()
);
}
}Opinione ed esperienza: il beneficio più evidente è la riusabilità. Ma per me il vero potere dei Selector sta in tre aspetti. Primo, coerenza, che evita le famigerate eccezioni “SObject row was retrieved via SOQL without querying the requested field”. Secondo, ottimizzazione, perché centralizzare le query rende facile implementare caching. Terzo, sicurezza. In un caso reale, il pattern dei Selector non solo ha reso le query più efficienti, ma ha anche permesso al team di creare facilmente query personalizzate, riducendo duplicazioni e minimizzando il rischio di SOQL injection.
Service Layer: il cervello dell’operazione
Se il Domain si concentra su un singolo record, il Service è l’orchestratore dei processi di business completi. È il livello che coordina le interazioni tra diversi domain e selector per soddisfare un caso d’uso.
Per esempio, un servizio come LeadConversionService potrebbe:
- Chiamare
LeadsSelectorper ottenere i dati del Lead. - Chiamare
AccountsSelectorper verificare se esiste già un account. - Invocare
AccountsDomaineContactsDomainper preparare i nuovi record. - Usare lo
UnitOfWorkper registrare la creazione di Account, Contact e l’aggiornamento del Lead.
// ILeadConversionService.cls
public interface ILeadConversionService {
void convertLeads(Set<Id> leadIds);
}
// LeadConversionService.cls
public class LeadConversionService implements ILeadConversionService {
private fflib_ISObjectUnitOfWork uow;
// ... Iniezione di dipendenze per selector e altri servizi
public void convertLeads(Set<Id> leadIds) {
// 1. Orchestrare la logica...
// 2. Chiamare i selector...
// 3. Usare i domain per applicare le regole...
// 4. Registrare le modifiche nello Unit of Work...
uow.commitWork();
}
}Opinione ed esperienza: il Service Layer è la colla che tiene insieme l’architettura. In un’applicazione reale, ho visto il service agire come mediatore (Mediator Pattern) tra le diverse parti del sistema, favorendo il riuso di codice e riducendo gli errori. Agendo come facciata (Facade Pattern), fornisce una chiara API di business. Questo significa che un trigger, un LWC o un’API esterna possono chiamare lo stesso servizio, garantendo che la logica venga eseguita in modo identico ovunque.
Unit of Work: transazioni sicure e atomiche
Lo Unit of Work è, a mio avviso, uno dei gioielli di fflib. La sua funzione è semplice ma rivoluzionaria per Apex: disaccoppia la logica di business dalle operazioni DML.
Invece di eseguire subito un insert o update, si registra l’intenzione di farlo in un’istanza di fflib_SObjectUnitOfWork.
// Ottenere un'istanza dello Unit of Work
fflib_ISObjectUnitOfWork uow = Application.UnitOfWork.newInstance();
// Registrare le operazioni invece di eseguirle
uow.registerNew(newAccount);
uow.registerDirty(existingContact);
uow.registerDeleted(oldOpportunity);
// ... altra logica di business ...
// Infine, confermare tutte le modifiche in un'unica transazione
uow.commitWork();Opinione ed esperienza: lo Unit of Work offre due benefici chiave: atomicità transazionale ed efficienza DML. Raggruppa tutte le operazioni dello stesso tipo (es. tutti gli insert su Account) in una singola chiamata DML, fondamentale per rimanere entro i governor limits. Ancora più importante è l’atomicità. Un team con cui ho lavorato ha riportato che lo UoW ha garantito la consistenza dei dati raggruppando le operazioni in un’unica transazione e rendendo i rollback estremamente semplici.
Tuttavia, è fondamentale comprendere questa atomicità negli scenari bulk. La sua natura è strettamente “tutto o niente”. Significa che se un singolo record in un batch di 200 fallisce la validazione, l’intera transazione viene annullata e nessun record viene salvato. Non è che non “bulkifichi” in termini di efficienza DML, ma il suo obiettivo è l’integrità totale rispetto al successo parziale. Pertanto, quando è necessario processare record in massa e si preferisce salvare quelli validi scartando quelli in errore, la strategia giusta è spesso progettare servizi che gestiscano batch più piccoli o usare metodi nativi come Database.insert(records, allOrNone: false) al di fuori del pattern UoW.
La potenza del mocking: veri unit test in Apex
Qui fflib brilla davvero e giustifica qualsiasi curva di apprendimento. Grazie alla separazione dei livelli e all’uso delle interfacce, il framework fflib Apex Mocks consente di scrivere unit test veramente isolati.
Possiamo testare la logica di un service senza toccare il database. Come? “Mockando” le sue dipendenze. Diciamo al test: “Quando il service chiama LeadsSelector, non andare al database; restituisci invece questa lista di Lead preparata”.
Questo permette di verificare la logica pura del servizio in modo rapido e deterministico. I test girano in millisecondi invece che in secondi, accelerando drasticamente i cicli CI/CD.
Conclusione: fflib come framework, non dogma
Ho visto team sopraffatti nel tentativo di implementare fflib al 100% fin dal primo giorno. Il mio consiglio è di considerarlo un framework di strumenti, non un dogma inflessibile.
Non serve adottarlo tutto in una volta. In base alla mia esperienza, il percorso più pragmatico è:
- Partire da Selector e Service: organizzare query e logica di business è già una vittoria enorme.
- Introdurre lo Unit of Work: una volta che i service sono in sede, la gestione centralizzata del DML è il passo naturale.
- Adottare i Domain gradualmente: il refactoring dei trigger per usare il Domain pattern può essere l’ultimo passo, poiché spesso richiede uno sforzo più coordinato.
Alla fine, fflib fornisce uno standard architetturale collaudato che porta a sistemi più manutenibili, scalabili e robusti. Il successo non sta nel seguire ciecamente le regole, ma nel comprendere i principi e applicarli con buon senso per costruire software di qualità sulla piattaforma Salesforce. La ricompensa è un codice di cui essere orgogliosi e uno sviluppo più agile nel lungo periodo.
Articoli Correlati
 Salesforce
Salesforce Bulk DML Service Pattern: Operazioni DML Parziali in Salesforce
Documentazione tecnica completa del framework Bulk DML Service Pattern per Salesforce. Impara a realizzare operazioni DML resilienti con successo parziale usando un API familiare in stile Unit of Work.
 Salesforce In evidenza
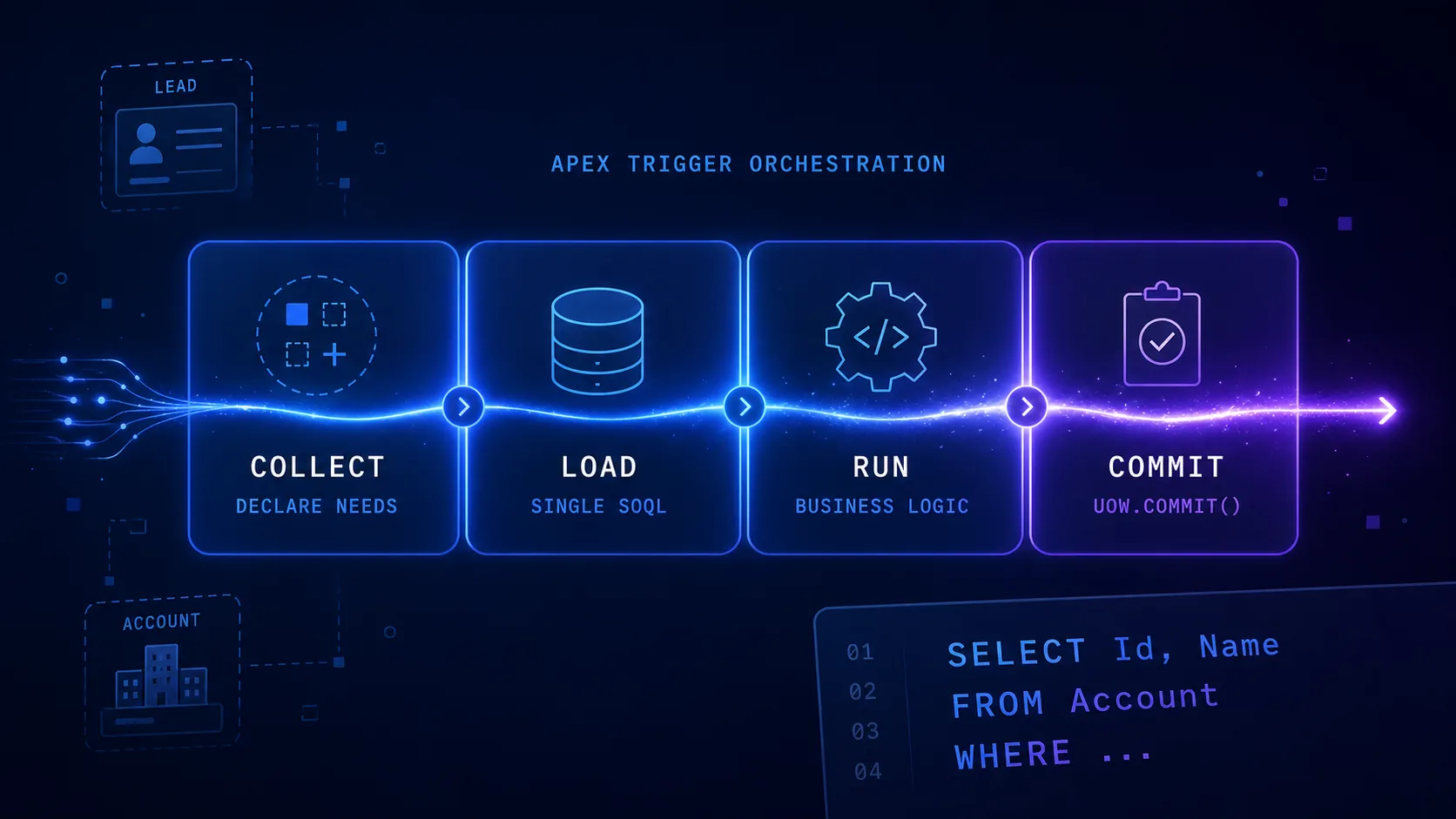
Salesforce In evidenza Query Plan Architecture: Pattern per i Trigger Apex
Scopri come strutturare trigger complessi in Salesforce con il pattern Query Plan Architecture. Separa la logica in 4 fasi (Collect, Load, Run, Commit) per eliminare SOQL duplicati, rispettare i governor limit e semplificare il testing.
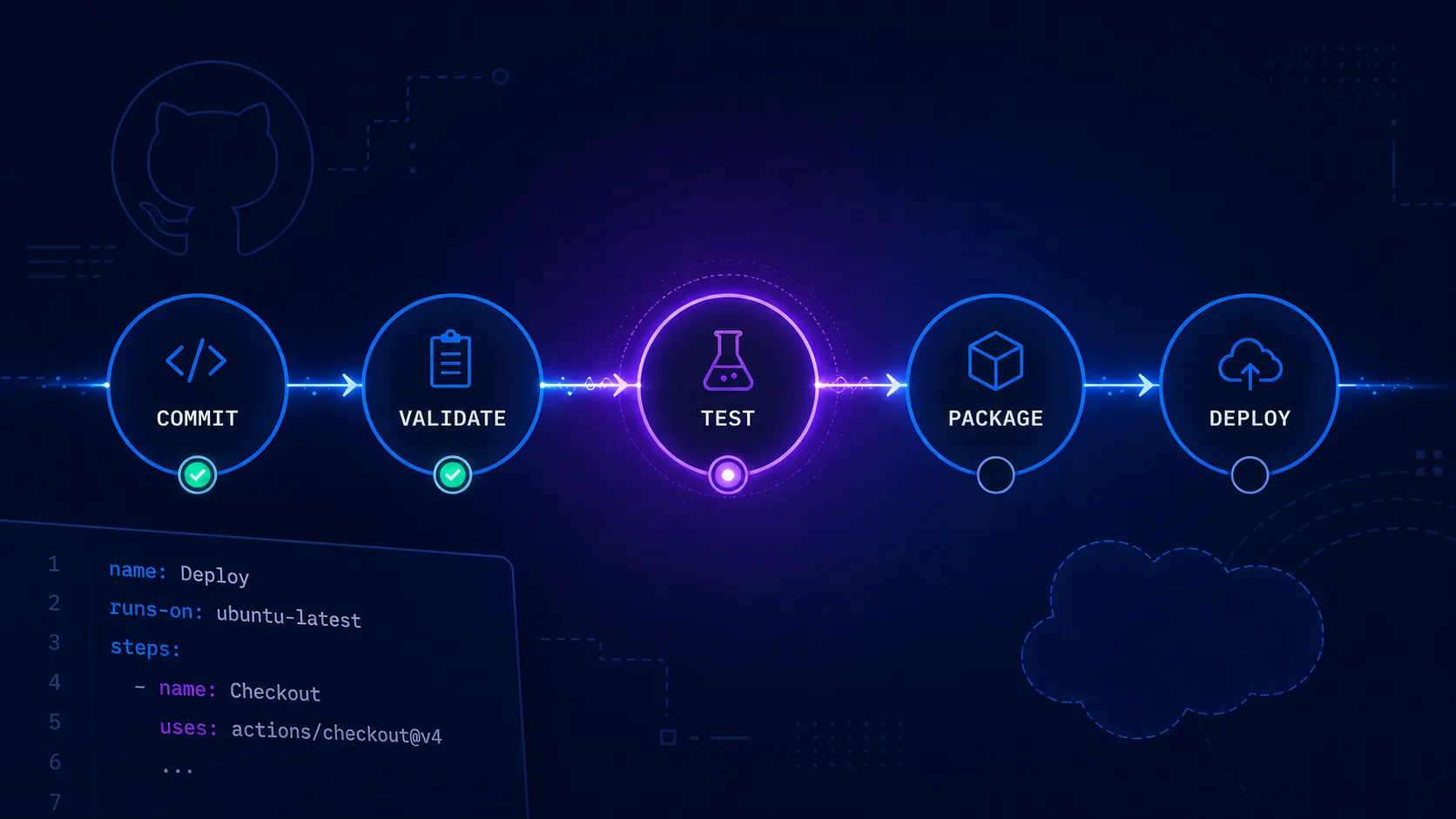 Salesforce In evidenza
Salesforce In evidenza CI/CD per Salesforce: Automazione dei Deploy
Implementazione completa di pipeline CI/CD per Salesforce usando GitHub Actions, SFDX CLI e Scratch Orgs. Include best practice e troubleshooting.